 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Exploring Hallucination of Large Multimodal Models in Video Understanding: Benchmark, Analysis and Mitigation
Mar 25, 2025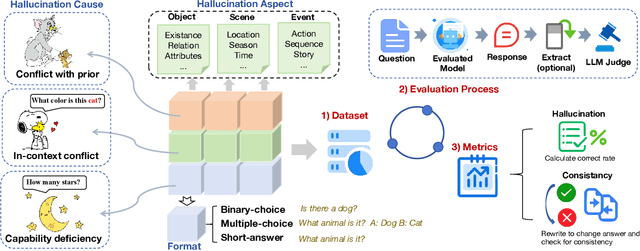
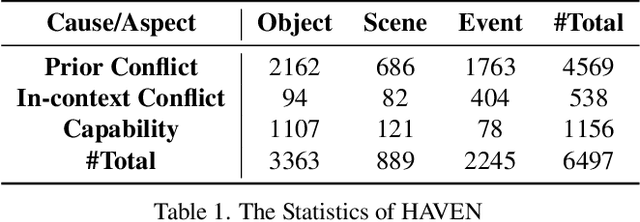
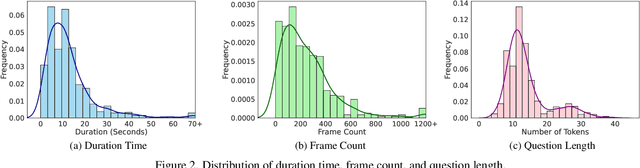
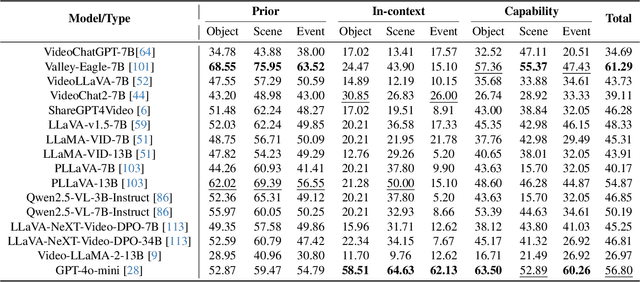
The hallucination of large multimodal models (LMMs), providing responses that appear correct but are actually incorrect, limits their reliability and applicability. This paper aims to study the hallucination problem of LMMs in video modality, which is dynamic and more challenging compared to static modalities like images and text. From this motivation, we first present a comprehensive benchmark termed HAVEN for evaluating hallucinations of LMMs in video understanding tasks. It is built upon three dimensions, i.e., hallucination causes, hallucination aspects, and question formats, resulting in 6K questions. Then, we quantitatively study 7 influential factors on hallucinations, e.g., duration time of videos, model sizes, and model reasoning, via experiments of 16 LMMs on the presented benchmark. In addition, inspired by recent thinking models like OpenAI o1, we propose a video-thinking model to mitigate the hallucinations of LMMs via supervised reasoning fine-tuning (SRFT) and direct preference optimization (TDPO)-- where SRFT enhances reasoning capabilities while TDPO reduces hallucinations in the thinking process. Extensive experiments and analyses demonstrate the effectiveness. Remarkably, it improves the baseline by 7.65% in accuracy on hallucination evaluation and reduces the bias score by 4.5%. The code and data are public at https://github.com/Hongcheng-Gao/HAVEN.
Treble Counterfactual VLMs: A Causal Approach to Hallucination
Mar 08, 2025

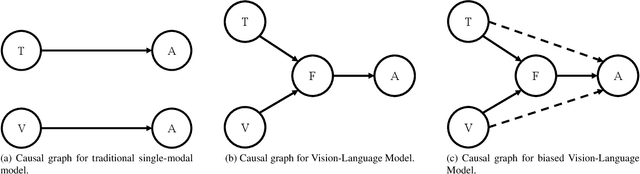

Vision-Language Models (VLMs) have advanced multi-modal tasks like image captioning, visual question answering, and reasoning. However, they often generate hallucinated outputs inconsistent with the visual context or prompt, limiting reliability in critical applications like autonomous driving and medical imaging. Existing studies link hallucination to statistical biases, language priors, and biased feature learning but lack a structured causal understanding. In this work, we introduce a causal perspective to analyze and mitigate hallucination in VLMs. We hypothesize that hallucination arises from unintended direct influences of either the vision or text modality, bypassing proper multi-modal fusion. To address this, we construct a causal graph for VLMs and employ counterfactual analysis to estimate the Natural Direct Effect (NDE) of vision, text, and their cross-modal interaction on the output. We systematically identify and mitigate these unintended direct effects to ensure that responses are primarily driven by genuine multi-modal fusion. Our approach consists of three steps: (1) designing structural causal graphs to distinguish correct fusion pathways from spurious modality shortcuts, (2) estimating modality-specific and cross-modal NDE using perturbed image representations, hallucinated text embeddings, and degraded visual inputs, and (3) implementing a test-time intervention module to dynamically adjust the model's dependence on each modality. Experimental results demonstrate that our method significantly reduces hallucination while preserving task performance, providing a robust and interpretable framework for improving VLM reliability. To enhance accessibility and reproducibility, our code is publicly available at https://github.com/TREE985/Treble-Counterfactual-VLMs.