 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient LiDAR Reflectance Compression via Scanning Serialization
May 14, 2025Reflectance attributes in LiDAR point clouds provide essential information for downstream tasks but remain underexplored in neural compression methods. To address this, we introduce SerLiC, a serialization-based neural compression framework to fully exploit the intrinsic characteristics of LiDAR reflectance. SerLiC first transforms 3D LiDAR point clouds into 1D sequences via scan-order serialization, offering a device-centric perspective for reflectance analysis. Each point is then tokenized into a contextual representation comprising its sensor scanning index, radial distance, and prior reflectance, for effective dependencies exploration. For efficient sequential modeling, Mamba is incorporated with a dual parallelization scheme, enabling simultaneous autoregressive dependency capture and fast processing. Extensive experiments demonstrate that SerLiC attains over 2x volume reduction against the original reflectance data, outperforming the state-of-the-art method by up to 22% reduction of compressed bits while using only 2% of its parameters. Moreover, a lightweight version of SerLiC achieves > 10 fps (frames per second) with just 111K parameters, which is attractive for real-world applications.
RENO: Real-Time Neural Compression for 3D LiDAR Point Clouds
Mar 16, 2025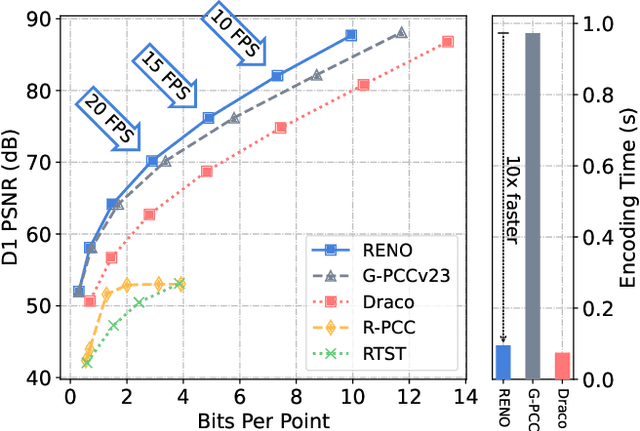
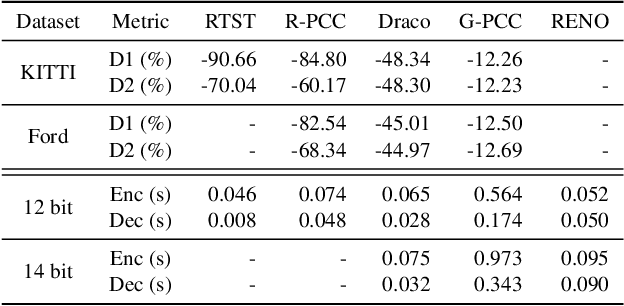
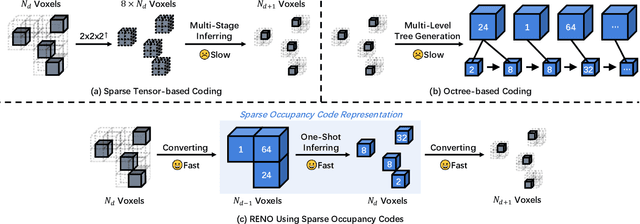
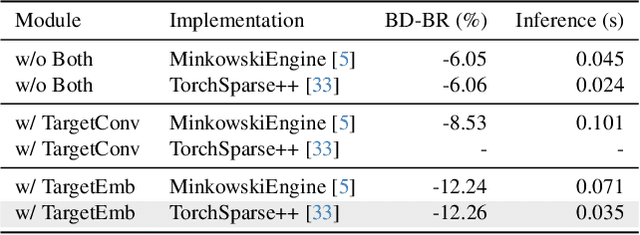
Despite the substantial advancements demonstrated by learning-based neural models in the LiDAR Point Cloud Compression (LPCC) task, realizing real-time compression - an indispensable criterion for numerous industrial applications - remains a formidable challenge. This paper proposes RENO, the first real-time neural codec for 3D LiDAR point clouds, achieving superior performance with a lightweight model. RENO skips the octree construction and directly builds upon the multiscale sparse tensor representation. Instead of the multi-stage inferring, RENO devises sparse occupancy codes, which exploit cross-scale correlation and derive voxels' occupancy in a one-shot manner, greatly saving processing time. Experimental results demonstrate that the proposed RENO achieves real-time coding speed, 10 fps at 14-bit depth on a desktop platform (e.g., one RTX 3090 GPU) for both encoding and decoding processes, while providing 12.25% and 48.34% bit-rate savings compared to G-PCCv23 and Draco, respectively, at a similar quality. RENO model size is merely 1MB, making it attractive for practical applications. The source code is available at https://github.com/NJUVISION/RENO.
High-Efficiency Neural Video Compression via Hierarchical Predictive Learning
Oct 03, 2024


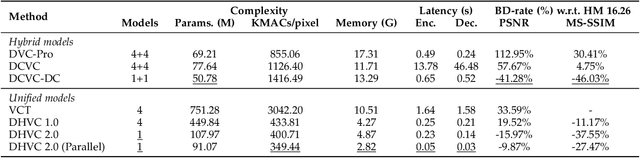
The enhanced Deep Hierarchical Video Compression-DHVC 2.0-has been introduced. This single-model neural video codec operates across a broad range of bitrates, delivering not only superior compression performance to representative methods but also impressive complexity efficiency, enabling real-time processing with a significantly smaller memory footprint on standard GPUs. These remarkable advancements stem from the use of hierarchical predictive coding. Each video frame is uniformly transformed into multiscale representations through hierarchical variational autoencoders. For a specific scale's feature representation of a frame, its corresponding latent residual variables are generated by referencing lower-scale spatial features from the same frame and then conditionally entropy-encoded using a probabilistic model whose parameters are predicted using same-scale temporal reference from previous frames and lower-scale spatial reference of the current frame. This feature-space processing operates from the lowest to the highest scale of each frame, completely eliminating the need for the complexity-intensive motion estimation and compensation techniques that have been standard in video codecs for decades. The hierarchical approach facilitates parallel processing, accelerating both encoding and decoding, and supports transmission-friendly progressive decoding, making it particularly advantageous for networked video applications in the presence of packet loss. Source codes will be made available.
Pointsoup: High-Performance and Extremely Low-Decoding-Latency Learned Geometry Codec for Large-Scale Point Cloud Scenes
Apr 21, 2024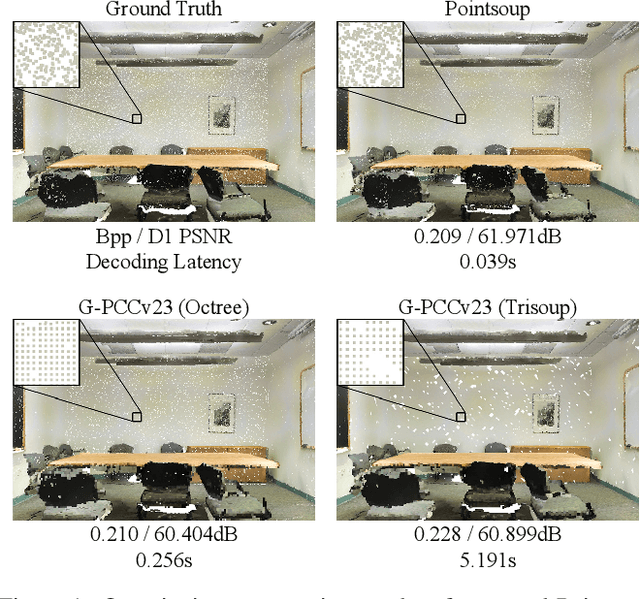

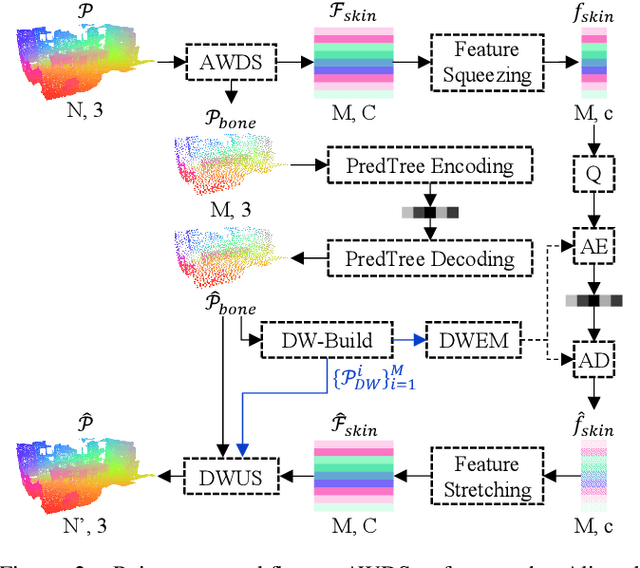
Despite considerable progress being achieved in point cloud geometry compression, there still remains a challenge in effectively compressing large-scale scenes with sparse surfaces. Another key challenge lies in reducing decoding latency, a crucial requirement in real-world application. In this paper, we propose Pointsoup, an efficient learning-based geometry codec that attains high-performance and extremely low-decoding-latency simultaneously. Inspired by conventional Trisoup codec, a point model-based strategy is devised to characterize local surfaces. Specifically, skin features are embedded from local windows via an attention-based encoder, and dilated windows are introduced as cross-scale priors to infer the distribution of quantized features in parallel. During decoding, features undergo fast refinement, followed by a folding-based point generator that reconstructs point coordinates with fairly fast speed. Experiments show that Pointsoup achieves state-of-the-art performance on multiple benchmarks with significantly lower decoding complexity, i.e., up to 90$\sim$160$\times$ faster than the G-PCCv23 Trisoup decoder on a comparatively low-end platform (e.g., one RTX 2080Ti). Furthermore, it offers variable-rate control with a single neural model (2.9MB), which is attractive for industrial practitioners.
Another Way to the Top: Exploit Contextual Clustering in Learned Image Coding
Jan 21, 2024



While convolution and self-attention are extensively used in learned image compression (LIC) for transform coding, this paper proposes an alternative called Contextual Clustering based LIC (CLIC) which primarily relies on clustering operations and local attention for correlation characterization and compact representation of an image. As seen, CLIC expands the receptive field into the entire image for intra-cluster feature aggregation. Afterward, features are reordered to their original spatial positions to pass through the local attention units for inter-cluster embedding. Additionally, we introduce the Guided Post-Quantization Filtering (GuidedPQF) into CLIC, effectively mitigating the propagation and accumulation of quantization errors at the initial decoding stage. Extensive experiments demonstrate the superior performance of CLIC over state-of-the-art works: when optimized using MSE, it outperforms VVC by about 10% BD-Rate in three widely-used benchmark datasets; when optimized using MS-SSIM, it saves more than 50% BD-Rate over VVC. Our CLIC offers a new way to generate compact representations for image compression, which also provides a novel direction along the line of LIC development.
Lossless Point Cloud Attribute Compression Using Cross-scale, Cross-group, and Cross-color Prediction
Mar 22, 2023This work extends the multiscale structure originally developed for point cloud geometry compression to point cloud attribute compression. To losslessly encode the attribute while maintaining a low bitrate, accurate probability prediction is critical. With this aim, we extensively exploit cross-scale, cross-group, and cross-color correlations of point cloud attribute to ensure accurate probability estimation and thus high coding efficiency. Specifically, we first generate multiscale attribute tensors through average pooling, by which, for any two consecutive scales, the decoded lower-scale attribute can be used to estimate the attribute probability in the current scale in one shot. Additionally, in each scale, we perform the probability estimation group-wisely following a predefined grouping pattern. In this way, both cross-scale and (same-scale) cross-group correlations are exploited jointly. Furthermore, cross-color redundancy is removed by allowing inter-color processing for YCoCg/RGB alike multi-channel attributes. The proposed method not only demonstrates state-of-the-art compression efficiency with significant performance gains over the latest G-PCC on various contents but also sustains low complexity with affordable encoding and decoding runtime.
Dynamic Point Cloud Geometry Compression Using Multiscale Inter Conditional Coding
Jan 28, 2023
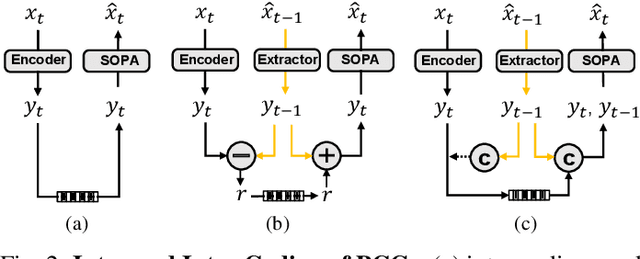
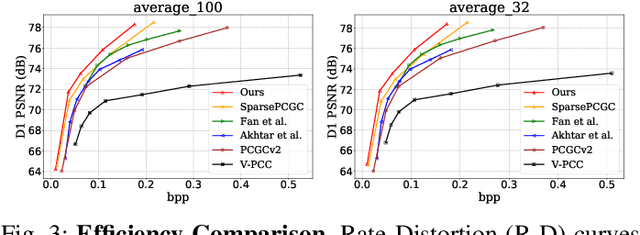

This work extends the Multiscale Sparse Representation (MSR) framework developed for static Point Cloud Geometry Compression (PCGC) to support the dynamic PCGC through the use of multiscale inter conditional coding. To this end, the reconstruction of the preceding Point Cloud Geometry (PCG) frame is progressively downscaled to generate multiscale temporal priors which are then scale-wise transferred and integrated with lower-scale spatial priors from the same frame to form the contextual information to improve occupancy probability approximation when processing the current PCG frame from one scale to another. Following the Common Test Conditions (CTC) defined in the standardization committee, the proposed method presents State-Of-The-Art (SOTA) compression performance, yielding 78% lossy BD-Rate gain to the latest standard-compliant V-PCC and 45% lossless bitrate reduction to the latest G-PCC. Even for recently-emerged learning-based solutions, our method still shows significant performance gains.
CARNet:Compression Artifact Reduction for Point Cloud Attribute
Sep 17, 2022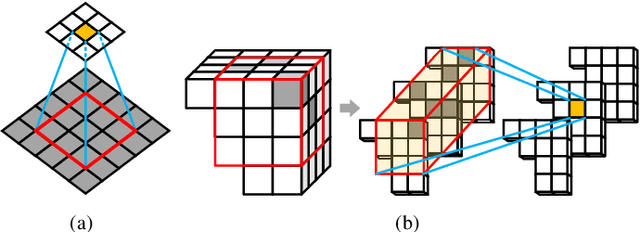

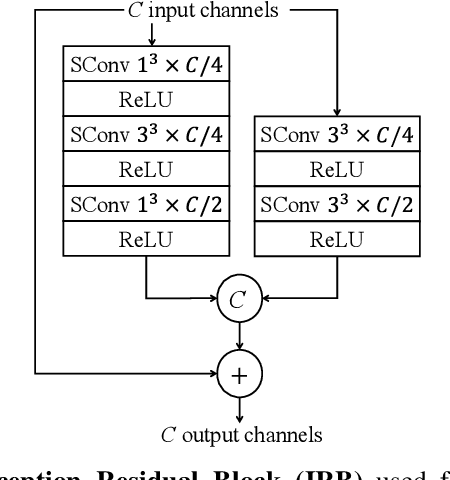
A learning-based adaptive loop filter is developed for the Geometry-based Point Cloud Compression (G-PCC) standard to reduce attribute compression artifacts. The proposed method first generates multiple Most-Probable Sample Offsets (MPSOs) as potential compression distortion approximations, and then linearly weights them for artifact mitigation. As such, we drive the filtered reconstruction as close to the uncompressed PCA as possible. To this end, we devise a Compression Artifact Reduction Network (CARNet) which consists of two consecutive processing phases: MPSOs derivation and MPSOs combination. The MPSOs derivation uses a two-stream network to model local neighborhood variations from direct spatial embedding and frequency-dependent embedding, where sparse convolutions are utilized to best aggregate information from sparsely and irregularly distributed points. The MPSOs combination is guided by the least square error metric to derive weighting coefficients on the fly to further capture content dynamics of input PCAs. The CARNet is implemented as an in-loop filtering tool of the GPCC, where those linear weighting coefficients are encapsulated into the bitstream with negligible bit rate overhead. Experimental results demonstrate significant improvement over the latest GPCC both subjectively and objectively.
Sparse Tensor-based Multiscale Representation for Point Cloud Geometry Compression
Nov 20, 2021
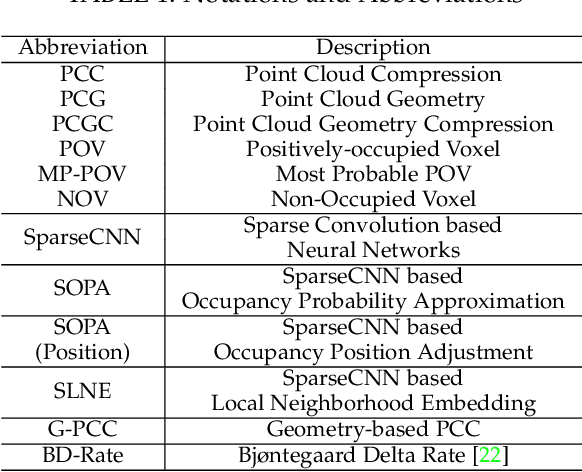
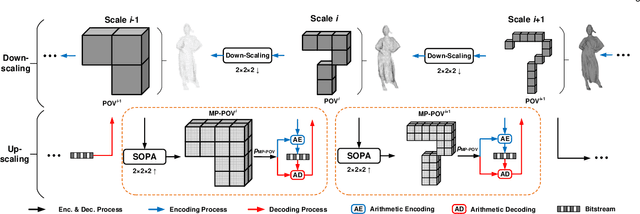
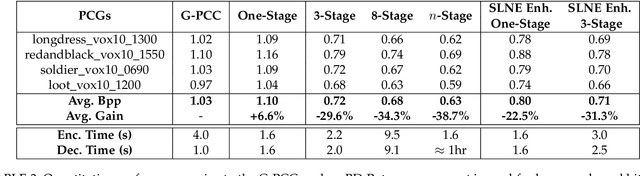
This study develops a unified Point Cloud Geometry (PCG) compression method through Sparse Tensor Processing (STP) based multiscale representation of voxelized PCG, dubbed as the SparsePCGC. Applying the STP reduces the complexity significantly because it only performs the convolutions centered at Most-Probable Positively-Occupied Voxels (MP-POV). And the multiscale representation facilitates us to compress scale-wise MP-POVs progressively. The overall compression efficiency highly depends on the approximation accuracy of occupancy probability of each MP-POV. Thus, we design the Sparse Convolution based Neural Networks (SparseCNN) consisting of sparse convolutions and voxel re-sampling to extensively exploit priors. We then develop the SparseCNN based Occupancy Probability Approximation (SOPA) model to estimate the occupancy probability in a single-stage manner only using the cross-scale prior or in multi-stage by step-wisely utilizing autoregressive neighbors. Besides, we also suggest the SparseCNN based Local Neighborhood Embedding (SLNE) to characterize the local spatial variations as the feature attribute to improve the SOPA. Our unified approach shows the state-of-art performance in both lossless and lossy compression modes across a variety of datasets including the dense PCGs (8iVFB, Owlii) and the sparse LiDAR PCGs (KITTI, Ford) when compared with the MPEG G-PCC and other popular learning-based compression schemes. Furthermore, the proposed method presents lightweight complexity due to point-wise computation, and tiny storage desire because of model sharing across all scales. We make all materials publicly accessible at https://github.com/NJUVISION/SparsePCGC for reproducible research.
Advances In Video Compression System Using Deep Neural Network: A Review And Case Studies
Jan 16, 2021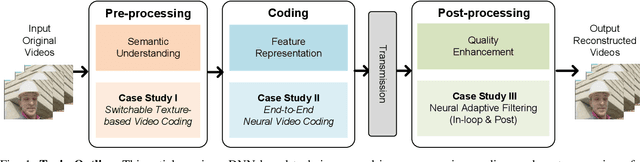
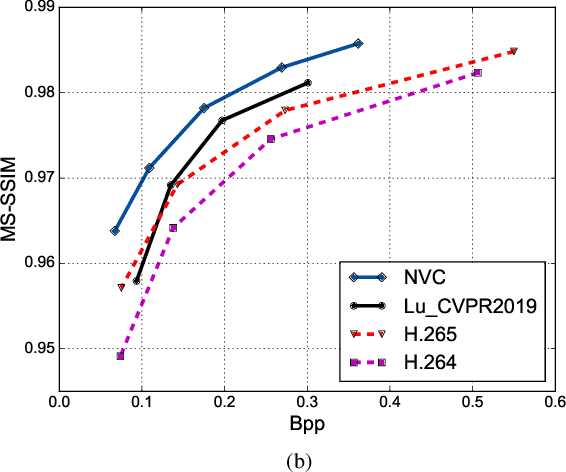


Significant advances in video compression system have been made in the past several decades to satisfy the nearly exponential growth of Internet-scale video traffic. From the application perspective, we have identified three major functional blocks including pre-processing, coding, and post-processing, that have been continuously investigated to maximize the end-user quality of experience (QoE) under a limited bit rate budget. Recently, artificial intelligence (AI) powered techniques have shown great potential to further increase the efficiency of the aforementioned functional blocks, both individually and jointly. In this article, we review extensively recent technical advances in video compression system, with an emphasis on deep neural network (DNN)-based approaches; and then present three comprehensive case studies. On pre-processing, we show a switchable texture-based video coding example that leverages DNN-based scene understanding to extract semantic areas for the improvement of subsequent video coder. On coding, we present an end-to-end neural video coding framework that takes advantage of the stacked DNNs to efficiently and compactly code input raw videos via fully data-driven learning. On post-processing, we demonstrate two neural adaptive filters to respectively facilitate the in-loop and post filtering for the enhancement of compressed frames. Finally, a companion website hosting the contents developed in this work can be accessed publicly at https://purdueviper.github.io/dnn-coding/.