 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Tensor-based Multiscale Representation for Point Cloud Geometry Compression
Nov 20, 2021
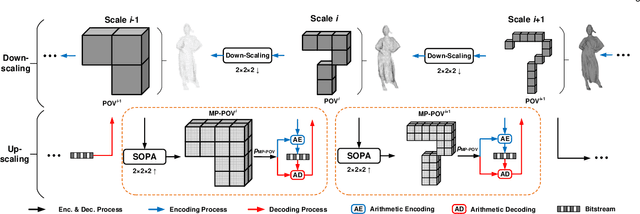
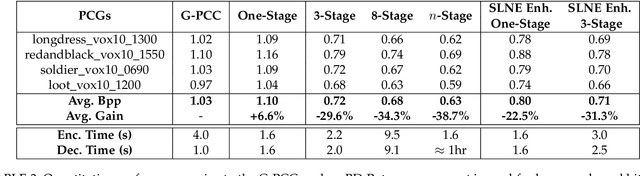
This study develops a unified Point Cloud Geometry (PCG) compression method through Sparse Tensor Processing (STP) based multiscale representation of voxelized PCG, dubbed as the SparsePCGC. Applying the STP reduces the complexity significantly because it only performs the convolutions centered at Most-Probable Positively-Occupied Voxels (MP-POV). And the multiscale representation facilitates us to compress scale-wise MP-POVs progressively. The overall compression efficiency highly depends on the approximation accuracy of occupancy probability of each MP-POV. Thus, we design the Sparse Convolution based Neural Networks (SparseCNN) consisting of sparse convolutions and voxel re-sampling to extensively exploit priors. We then develop the SparseCNN based Occupancy Probability Approximation (SOPA) model to estimate the occupancy probability in a single-stage manner only using the cross-scale prior or in multi-stage by step-wisely utilizing autoregressive neighbors. Besides, we also suggest the SparseCNN based Local Neighborhood Embedding (SLNE) to characterize the local spatial variations as the feature attribute to improve the SOPA. Our unified approach shows the state-of-art performance in both lossless and lossy compression modes across a variety of datasets including the dense PCGs (8iVFB, Owlii) and the sparse LiDAR PCGs (KITTI, Ford) when compared with the MPEG G-PCC and other popular learning-based compression schemes. Furthermore, the proposed method presents lightweight complexity due to point-wise computation, and tiny storage desire because of model sharing across all scales. We make all materials publicly accessible at https://github.com/NJUVISION/SparsePCGC for reproducible research.
Transformer-based Image Compression
Nov 12, 2021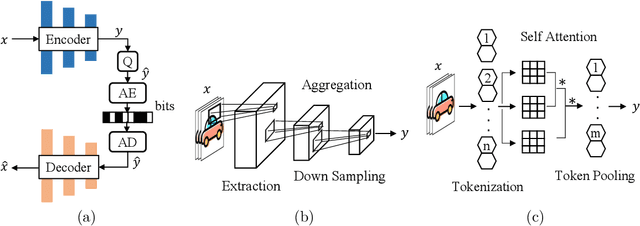
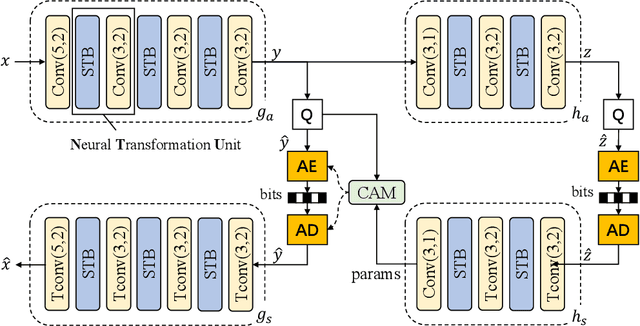
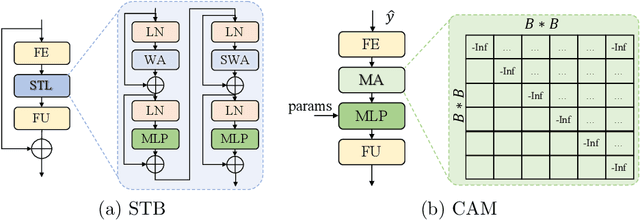
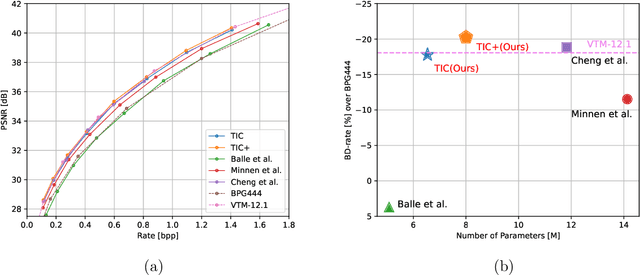
A Transformer-based Image Compression (TIC) approach is developed which reuses the canonical variational autoencoder (VAE) architecture with paired main and hyper encoder-decoders. Both main and hyper encoders are comprised of a sequence of neural transformation units (NTUs) to analyse and aggregate important information for more compact representation of input image, while the decoders mirror the encoder-side operations to generate pixel-domain image reconstruction from the compressed bitstream. Each NTU is consist of a Swin Transformer Block (STB) and a convolutional layer (Conv) to best embed both long-range and short-range information; In the meantime, a casual attention module (CAM) is devised for adaptive context modeling of latent features to utilize both hyper and autoregressive priors. The TIC rivals with state-of-the-art approaches including deep convolutional neural networks (CNNs) based learnt image coding (LIC) methods and handcrafted rules-based intra profile of recently-approved Versatile Video Coding (VVC) standard, and requires much less model parameters, e.g., up to 45% reduction to leading-performance LIC.