 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Prompt Management in GitHub Repositories: A Call for Best Practices
Sep 15, 2025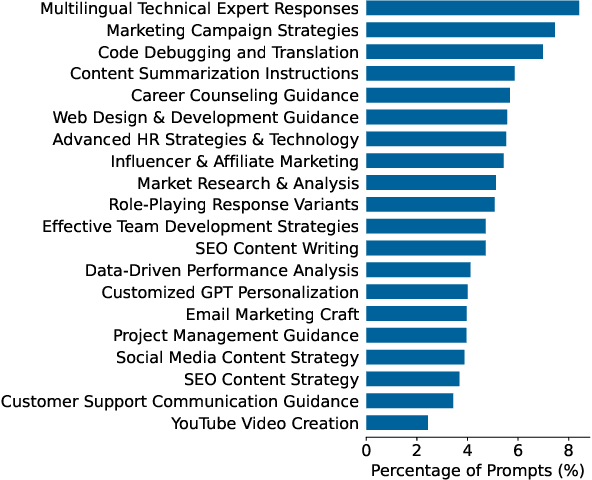
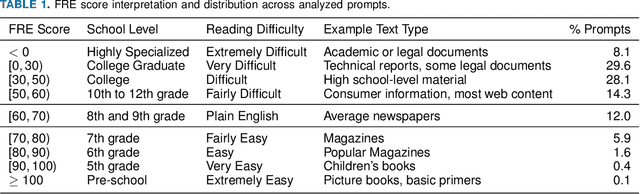
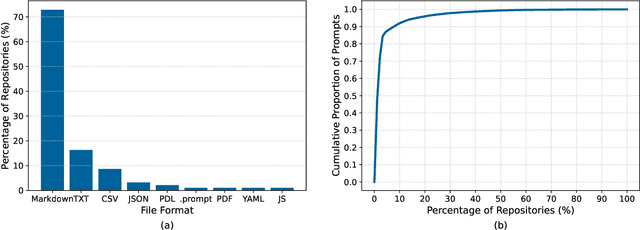

The rapid adoption of foundation models (e.g., large language models) has given rise to promptware, i.e., software built using natural language prompts. Effective management of prompts, such as organization and quality assurance, is essential yet challenging. In this study, we perform an empirical analysis of 24,800 open-source prompts from 92 GitHub repositories to investigate prompt management practices and quality attributes. Our findings reveal critical challenges such as considerable inconsistencies in prompt formatting, substantial internal and external prompt duplication, and frequent readability and spelling issues. Based on these findings, we provide actionable recommendations for developers to enhance the usability and maintainability of open-source prompts within the rapidly evolving promptware ecosystem.
The Hitchhikers Guide to Production-ready Trustworthy Foundation Model powered Software (FMware)
May 15, 2025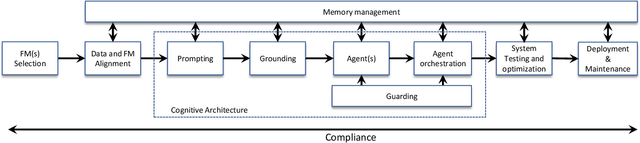
Foundation Models (FMs) such as Large Language Models (LLMs) are reshaping the software industry by enabling FMware, systems that integrate these FMs as core components. In this KDD 2025 tutorial, we present a comprehensive exploration of FMware that combines a curated catalogue of challenges with real-world production concerns. We first discuss the state of research and practice in building FMware. We further examine the difficulties in selecting suitable models, aligning high-quality domain-specific data, engineering robust prompts, and orchestrating autonomous agents. We then address the complex journey from impressive demos to production-ready systems by outlining issues in system testing, optimization, deployment, and integration with legacy software. Drawing on our industrial experience and recent research in the area, we provide actionable insights and a technology roadmap for overcoming these challenges. Attendees will gain practical strategies to enable the creation of trustworthy FMware in the evolving technology landscape.
InterTrans: Leveraging Transitive Intermediate Translations to Enhance LLM-based Code Translation
Nov 05, 2024



Code translation aims to convert a program from one programming language (PL) to another. This long-standing software engineering task is crucial for modernizing legacy systems, ensuring cross-platform compatibility, enhancing performance, and more. However, automating this process remains challenging due to many syntactic and semantic differences between PLs. Recent studies show that even advanced techniques such as large language models (LLMs), especially open-source LLMs, still struggle with the task. Currently, code LLMs are trained with source code from multiple programming languages, thus presenting multilingual capabilities. In this paper, we investigate whether such multilingual capabilities can be harnessed to enhance code translation. To achieve this goal, we introduce InterTrans, an LLM-based automated code translation approach that, in contrast to existing approaches, leverages intermediate translations across PLs to bridge the syntactic and semantic gaps between source and target PLs. InterTrans contains two stages. It first utilizes a novel Tree of Code Translation (ToCT) algorithm to plan transitive intermediate translation sequences between a given source and target PL, then validates them in a specific order. We evaluate InterTrans with three open LLMs on three benchmarks (i.e., CodeNet, HumanEval-X, and TransCoder) involving six PLs. Results show an absolute improvement between 18.3% to 43.3% in Computation Accuracy (CA) for InterTrans over Direct Translation with 10 attempts. The best-performing variant of InterTrans (with Magicoder LLM) achieved an average CA of 87.3%-95.4% on three benchmarks.
Exploring the Impact of the Output Format on the Evaluation of Large Language Models for Code Translation
Mar 25, 2024



Code translation between programming languages is a long-existing and critical task in software engineering, facilitating the modernization of legacy systems, ensuring cross-platform compatibility, and enhancing software performance. With the recent advances in large language models (LLMs) and their applications to code translation, there is an increasing need for comprehensive evaluation of these models. In this study, we empirically analyze the generated outputs of eleven popular instruct-tuned LLMs with parameters ranging from 1B up to 46.7B on 3,820 translation pairs across five languages, including C, C++, Go, Java, and Python. Our analysis found that between 26.4% and 73.7% of code translations produced by our evaluated LLMs necessitate post-processing, as these translations often include a mix of code, quotes, and text rather than being purely source code. Overlooking the output format of these models can inadvertently lead to underestimation of their actual performance. This is particularly evident when evaluating them with execution-based metrics such as Computational Accuracy (CA). Our results demonstrate that a strategic combination of prompt engineering and regular expression can effectively extract the source code from the model generation output. In particular, our method can help eleven selected models achieve an average Code Extraction Success Rate (CSR) of 92.73%. Our findings shed light on and motivate future research to conduct more reliable benchmarks of LLMs for code translation.
Rethinking Software Engineering in the Foundation Model Era: A Curated Catalogue of Challenges in the Development of Trustworthy FMware
Mar 04, 2024



Foundation models (FMs), such as Large Language Models (LLMs), have revolutionized software development by enabling new use cases and business models. We refer to software built using FMs as FMware. The unique properties of FMware (e.g., prompts, agents, and the need for orchestration), coupled with the intrinsic limitations of FMs (e.g., hallucination) lead to a completely new set of software engineering challenges. Based on our industrial experience, we identified 10 key SE4FMware challenges that have caused enterprise FMware development to be unproductive, costly, and risky. In this paper, we discuss these challenges in detail and state the path for innovation that we envision. Next, we present FMArts, which is our long-term effort towards creating a cradle-to-grave platform for the engineering of trustworthy FMware. Finally, we (i) show how the unique properties of FMArts enabled us to design and develop a complex FMware for a large customer in a timely manner and (ii) discuss the lessons that we learned in doing so. We hope that the disclosure of the aforementioned challenges and our associated efforts to tackle them will not only raise awareness but also promote deeper and further discussions, knowledge sharing, and innovative solutions across the software engineering discipline.