 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Error Analysis: Learning to Characterize Errors
Jan 14, 2022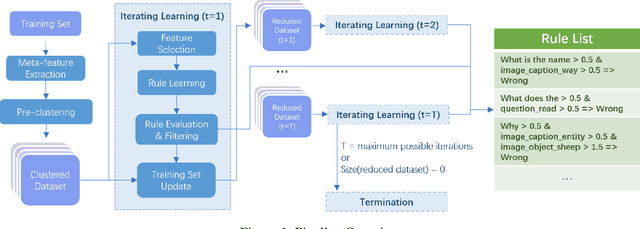

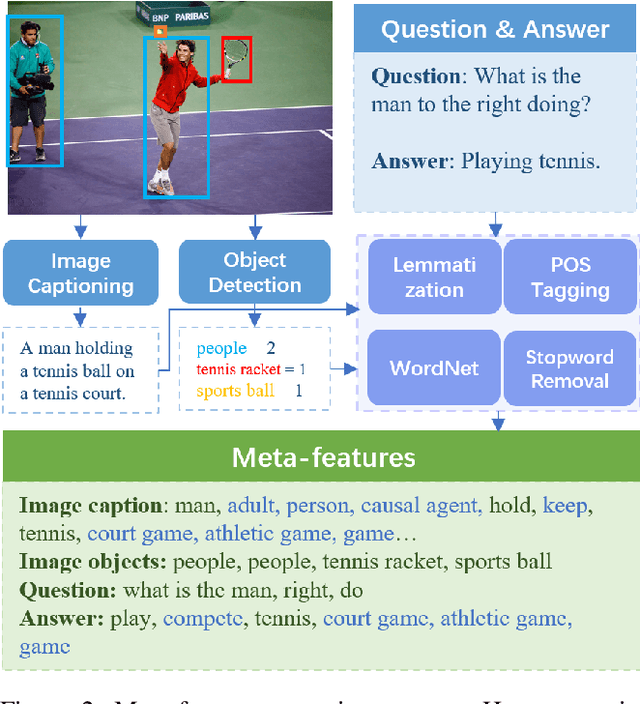

Characterizing the patterns of errors that a system makes helps researchers focus future development on increasing its accuracy and robustness. We propose a novel form of "meta learning" that automatically learns interpretable rules that characterize the types of errors that a system makes, and demonstrate these rules' ability to help understand and improve two NLP systems. Our approach works by collecting error cases on validation data, extracting meta-features describing these samples, and finally learning rules that characterize errors using these features. We apply our approach to VilBERT, for Visual Question Answering, and RoBERTa, for Common Sense Question Answering. Our system learns interpretable rules that provide insights into systemic errors these systems make on the given tasks. Using these insights, we are also able to "close the loop" and modestly improve performance of these systems.
Using Angle of Arrival for Improving Indoor Localization
Jan 25, 2021
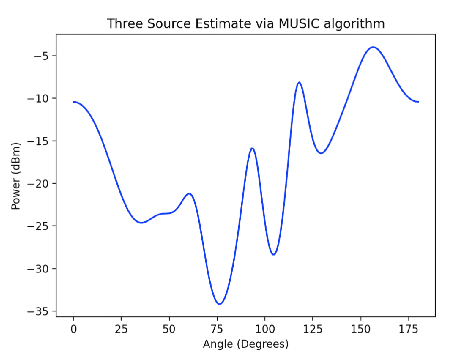
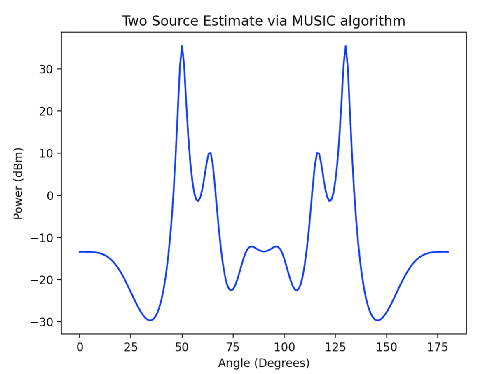
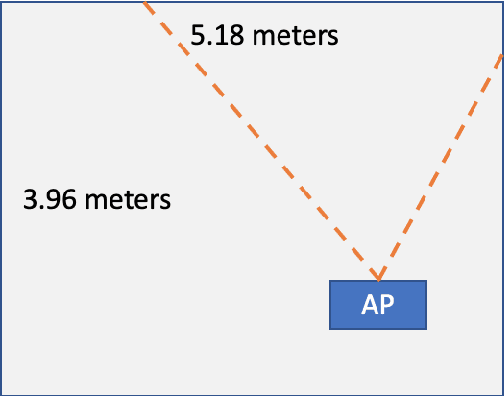
In this paper, we primarily explore the improvement of single stream audio systems using Angle of Arrival calculations in both simulation and real life gathered data. We wanted to learn how to discern the direction of an audio source from gathered signal data to ultimately incorporate into a multi modal security system. We focused on the MUSIC algorithm for the estimation of the angle of arrival but briefly experimented with other techniques such as Bartlett and Capo. We were able to implement our own MUSIC algorithm on stimulated data from Cornell. In addition, we demonstrated how we are able to calculate the angle of arrival over time in a real life scene. Finally, we are able to detect the direction of arrival for two separate and simultaneous audio sources in a real life scene. Eventually, we could incorporate this tracking into a multi modal system combined with video. Overall, we are able to produce compelling results for angle of arrival calculations that could be the stepping stones for a better system to detect events in a scene.
A Novel Information Theoretic Framework for Finding Semantic Similarity in WordNet
Jul 19, 2016


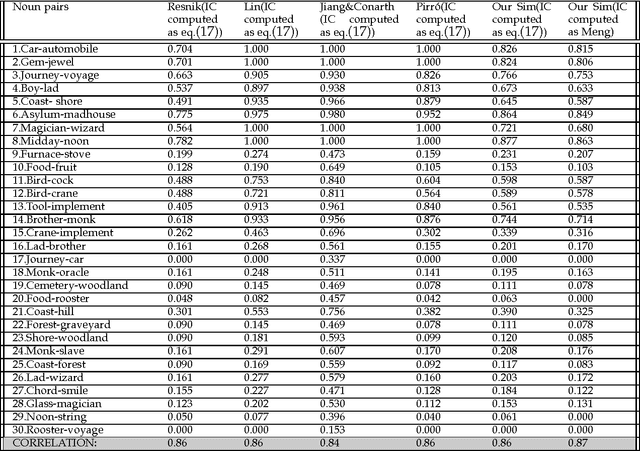
Information content (IC) based measures for finding semantic similarity is gaining preferences day by day. Semantics of concepts can be highly characterized by information theory. The conventional way for calculating IC is based on the probability of appearance of concepts in corpora. Due to data sparseness and corpora dependency issues of those conventional approaches, a new corpora independent intrinsic IC calculation measure has evolved. In this paper, we mainly focus on such intrinsic IC model and several topological aspects of the underlying ontology. Accuracy of intrinsic IC calculation and semantic similarity measure rely on these aspects deeply. Based on these analysis we propose an information theoretic framework which comprises an intrinsic IC calculator and a semantic similarity model. Our approach is compared with state of the art semantic similarity measures based on corpora dependent IC calculation as well as intrinsic IC based methods using several benchmark data set. We also compare our model with the related Edge based, Feature based and Distributional approaches. Experimental results show that our intrinsic IC model gives high correlation value when applied to different semantic similarity models. Our proposed semantic similarity model also achieves significant results when embedded with some state of the art IC models including ours.