 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach for Automatic Construction of an Algorithmic Knowledge Graph from Textual Resources
May 13, 2022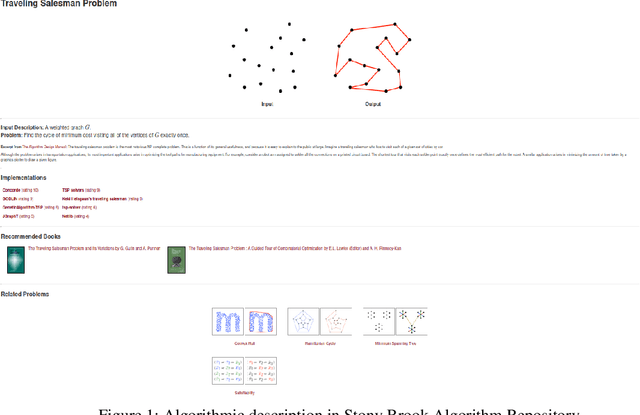



There is enormous growth in various fields of research. This development is accompanied by new problems. To solve these problems efficiently and in an optimized manner, algorithms are created and described by researchers in the scientific literature. Scientific algorithms are vital for understanding and reusing existing work in numerous domains. However, algorithms are generally challenging to find. Also, the comparison among similar algorithms is difficult because of the disconnected documentation. Information about algorithms is mostly present in websites, code comments, and so on. There is an absence of structured metadata to portray algorithms. As a result, sometimes redundant or similar algorithms are published, and the researchers build them from scratch instead of reusing or expanding upon the already existing algorithm. In this paper, we introduce an approach for automatically developing a knowledge graph (KG) for algorithmic problems from unstructured data. Because it captures information more clearly and extensively, an algorithm KG will give additional context and explainability to the algorithm metadata.
Models for Narrative Information: A Study
Sep 23, 2021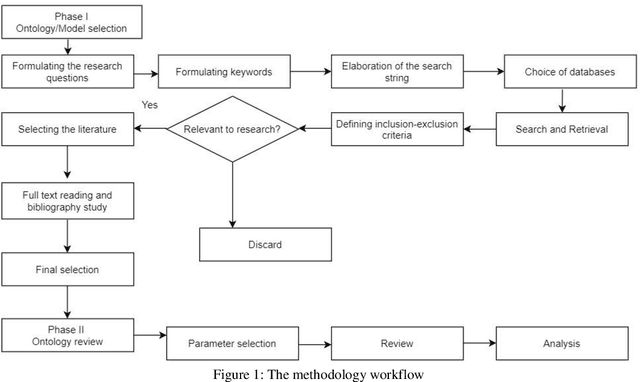
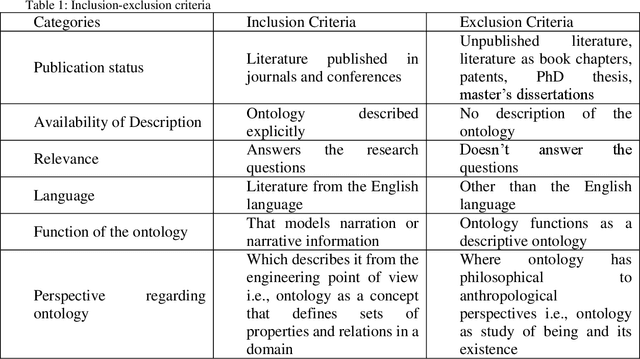
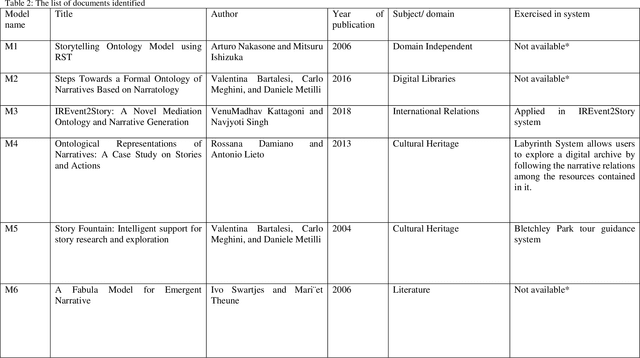
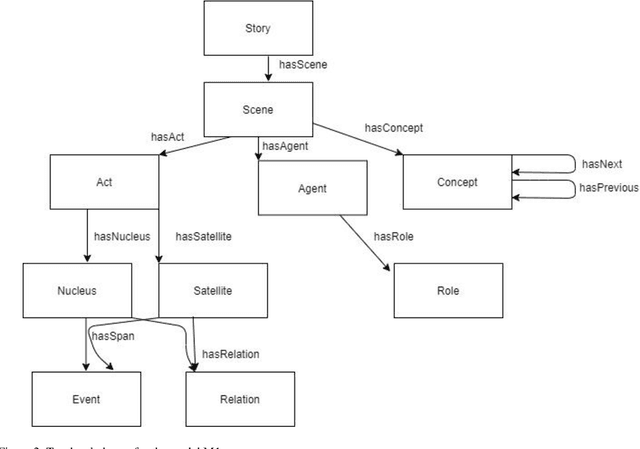
The major objective of this work is to study and report the existing ontology-driven models for narrative information. The paper aims to analyze these models across various domains. The goal of this work is to bring the relevant literature, and ontology models under one umbrella, and perform a parametric comparative study. A systematic literature review methodology was adopted for an extensive literature selection. A random stratified sampling technique was used to select the models from the literature. The findings explicate a comparative view of the narrative models across domains. The differences and similarities of knowledge representation across domains, in case of narrative information models based on ontology was identified. There are significantly fewer studies that reviewed the ontology-based narrative models. This work goes a step further by evaluating the ontologies using the parameters from narrative components. This paper will explore the basic concepts and top-level concepts in the models. Besides, this study provides a comprehensive study of the narrative theories in the context of ongoing research. The findings of this work demonstrate the similarities and differences among the elements of the ontology across domains. It also identifies the state of the art literature for ontology-based narrative information.
AMV : Algorithm Metadata Vocabulary
Jun 01, 2021


Metadata vocabularies are used in various domains of study. It provides an in-depth description of the resources. In this work, we develop Algorithm Metadata Vocabulary (AMV), a vocabulary for capturing and storing the metadata about the algorithms (a procedure or a set of rules that is followed step-by-step to solve a problem, especially by a computer). The snag faced by the researchers in the current time is the failure of getting relevant results when searching for algorithms in any search engine. AMV is represented as a semantic model and produced OWL file, which can be directly used by anyone interested to create and publish algorithm metadata as a knowledge graph, or to provide metadata service through SPARQL endpoint. To design the vocabulary, we propose a well-defined methodology, which considers real issues faced by the algorithm users and the practitioners. The evaluation shows a promising result.
A Novel Information Theoretic Framework for Finding Semantic Similarity in WordNet
Jul 19, 2016


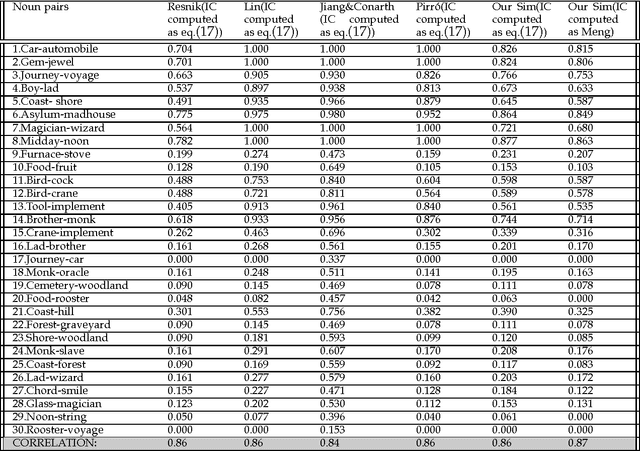
Information content (IC) based measures for finding semantic similarity is gaining preferences day by day. Semantics of concepts can be highly characterized by information theory. The conventional way for calculating IC is based on the probability of appearance of concepts in corpora. Due to data sparseness and corpora dependency issues of those conventional approaches, a new corpora independent intrinsic IC calculation measure has evolved. In this paper, we mainly focus on such intrinsic IC model and several topological aspects of the underlying ontology. Accuracy of intrinsic IC calculation and semantic similarity measure rely on these aspects deeply. Based on these analysis we propose an information theoretic framework which comprises an intrinsic IC calculator and a semantic similarity model. Our approach is compared with state of the art semantic similarity measures based on corpora dependent IC calculation as well as intrinsic IC based methods using several benchmark data set. We also compare our model with the related Edge based, Feature based and Distributional approaches. Experimental results show that our intrinsic IC model gives high correlation value when applied to different semantic similarity models. Our proposed semantic similarity model also achieves significant results when embedded with some state of the art IC models including ours.