 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterface Design for Self-Supervised Speech Models
Paper and Code
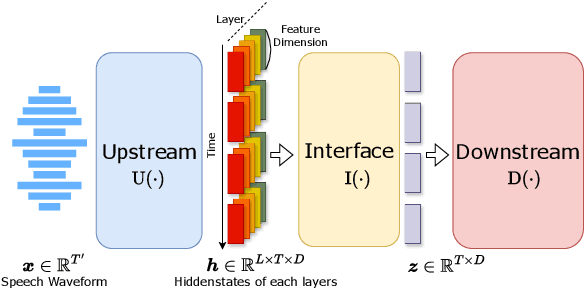
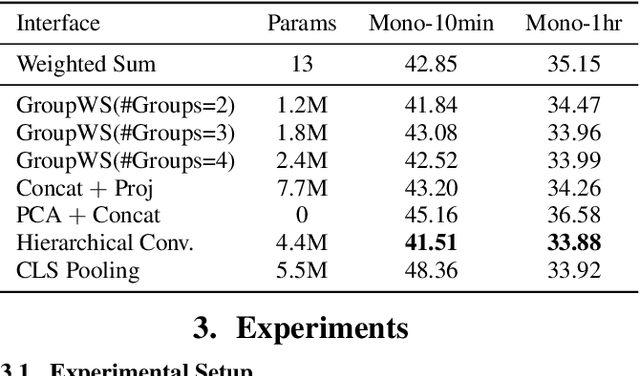
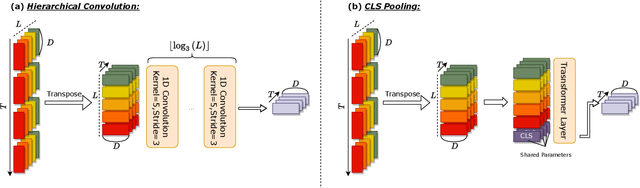
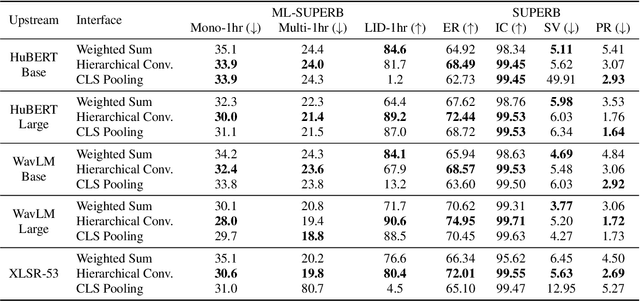
Self-supervised speech (SSL) models have recently become widely adopted for many downstream speech processing tasks. The general usage pattern is to employ SSL models as feature extractors, and then train a downstream prediction head to solve a specific task. However, different layers of SSL models have been shown to capture different types of information, and the methods of combining them are not well studied. To this end, we extend the general framework for SSL model utilization by proposing the interface that connects the upstream and downstream. Under this view, the dominant technique of combining features via a layerwise weighted sum can be regarded as a specific interface. We propose several alternative interface designs and demonstrate that the weighted sum interface is suboptimal for many tasks. In particular, we show that a convolutional interface whose depth scales logarithmically with the depth of the upstream model consistently outperforms many other interface designs.