 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-based Talking Video Editing with Cascaded Conditional Diffusion
Paper and Code
Jul 20, 2024
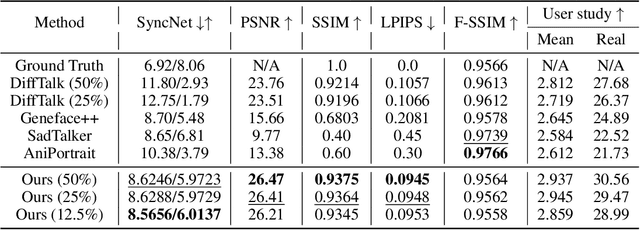


Text-based talking-head video editing aims to efficiently insert, delete, and substitute segments of talking videos through a user-friendly text editing approach. It is challenging because of \textbf{1)} generalizable talking-face representation, \textbf{2)} seamless audio-visual transitions, and \textbf{3)} identity-preserved talking faces. Previous works either require minutes of talking-face video training data and expensive test-time optimization for customized talking video editing or directly generate a video sequence without considering in-context information, leading to a poor generalizable representation, or incoherent transitions, or even inconsistent identity. In this paper, we propose an efficient cascaded conditional diffusion-based framework, which consists of two stages: audio to dense-landmark motion and motion to video. \textit{\textbf{In the first stage}}, we first propose a dynamic weighted in-context diffusion module to synthesize dense-landmark motions given an edited audio. \textit{\textbf{In the second stage}}, we introduce a warping-guided conditional diffusion module. The module first interpolates between the start and end frames of the editing interval to generate smooth intermediate frames. Then, with the help of the audio-to-dense motion images, these intermediate frames are warped to obtain coarse intermediate frames. Conditioned on the warped intermedia frames, a diffusion model is adopted to generate detailed and high-resolution target frames, which guarantees coherent and identity-preserved transitions. The cascaded conditional diffusion model decomposes the complex talking editing task into two flexible generation tasks, which provides a generalizable talking-face representation, seamless audio-visual transitions, and identity-preserved faces on a small dataset. Experiments show the effectiveness and superiority of the proposed method.