 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Exploring Textual and Speech information in Dialogue Act Classification with Speaker Domain Adaptation
Oct 17, 2018
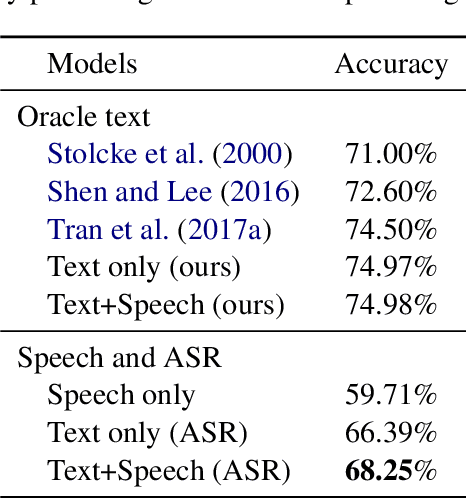
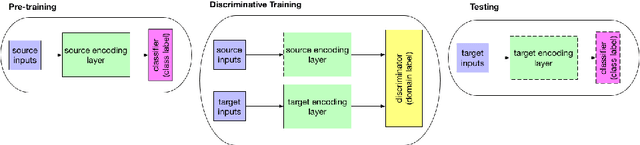

In spite of the recent success of Dialogue Act (DA) classification, the majority of prior works focus on text-based classification with oracle transcriptions, i.e. human transcriptions, instead of Automatic Speech Recognition (ASR)'s transcriptions. In spoken dialog systems, however, the agent would only have access to noisy ASR transcriptions, which may further suffer performance degradation due to domain shift. In this paper, we explore the effectiveness of using both acoustic and textual signals, either oracle or ASR transcriptions, and investigate speaker domain adaptation for DA classification. Our multimodal model proves to be superior to the unimodal models, particularly when the oracle transcriptions are not available. We also propose an effective method for speaker domain adaptation, which achieves competitive results.
SPEECH-COCO: 600k Visually Grounded Spoken Captions Aligned to MSCOCO Data Set
Aug 01, 2017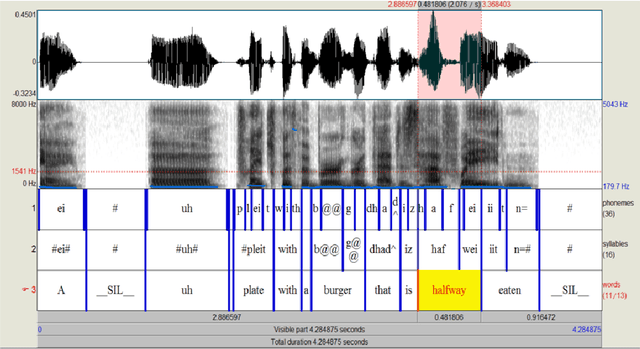
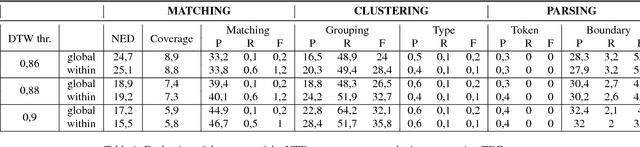
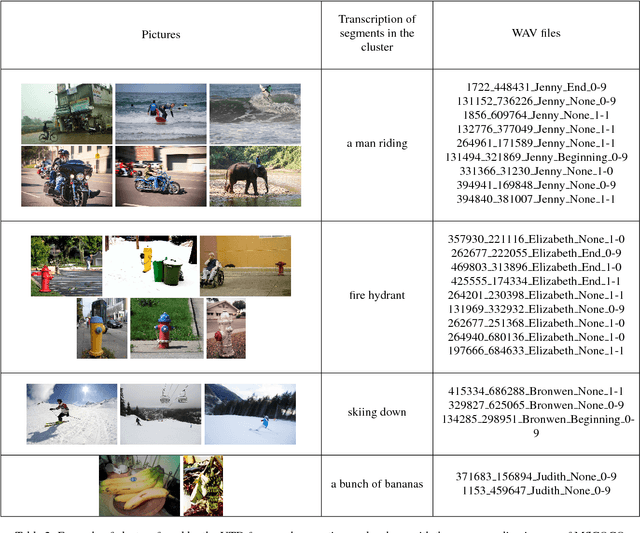
This paper presents an augmentation of MSCOCO dataset where speech is added to image and text. Speech captions are generated using text-to-speech (TTS) synthesis resulting in 616,767 spoken captions (more than 600h) paired with images. Disfluencies and speed perturbation are added to the signal in order to sound more natural. Each speech signal (WAV) is paired with a JSON file containing exact timecode for each word/syllable/phoneme in the spoken caption. Such a corpus could be used for Language and Vision (LaVi) tasks including speech input or output instead of text. Investigating multimodal learning schemes for unsupervised speech pattern discovery is also possible with this corpus, as demonstrated by a preliminary study conducted on a subset of the corpus (10h, 10k spoken captions).