 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPEECH-COCO: 600k Visually Grounded Spoken Captions Aligned to MSCOCO Data Set
Paper and Code
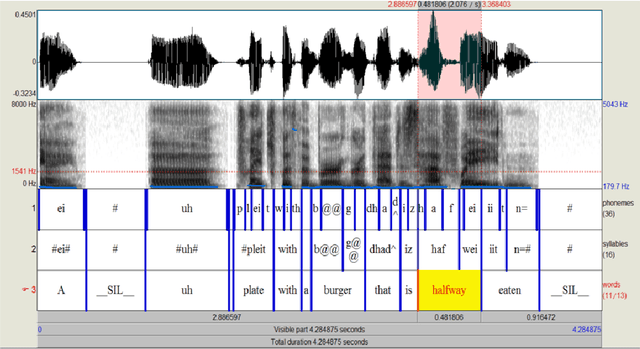
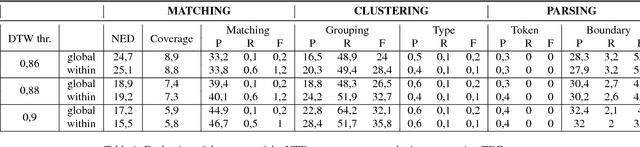
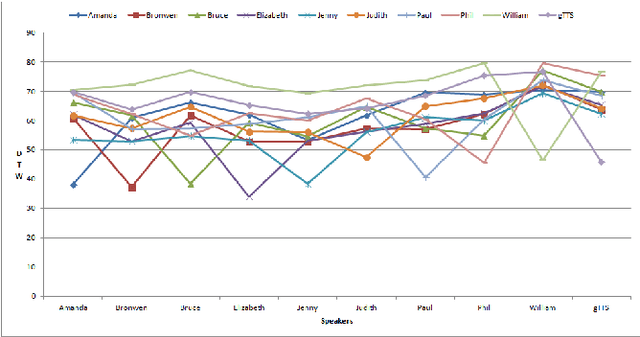
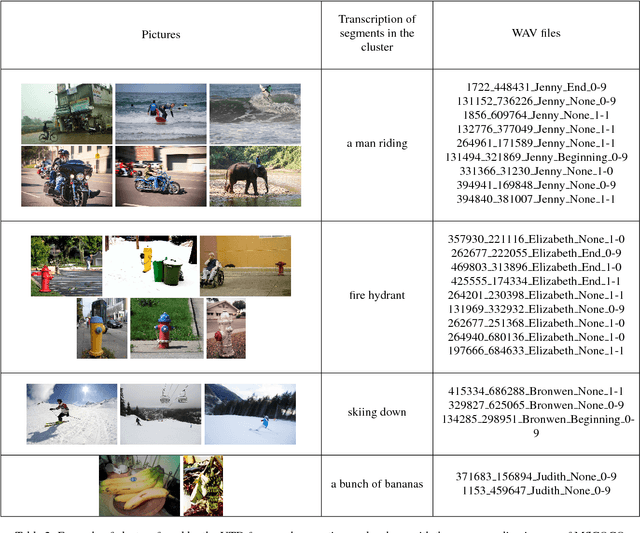
This paper presents an augmentation of MSCOCO dataset where speech is added to image and text. Speech captions are generated using text-to-speech (TTS) synthesis resulting in 616,767 spoken captions (more than 600h) paired with images. Disfluencies and speed perturbation are added to the signal in order to sound more natural. Each speech signal (WAV) is paired with a JSON file containing exact timecode for each word/syllable/phoneme in the spoken caption. Such a corpus could be used for Language and Vision (LaVi) tasks including speech input or output instead of text. Investigating multimodal learning schemes for unsupervised speech pattern discovery is also possible with this corpus, as demonstrated by a preliminary study conducted on a subset of the corpus (10h, 10k spoken captions).