 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximity-Based Non-uniform Abstractions for Approximate Planning
Paper and Code
Jan 18, 2014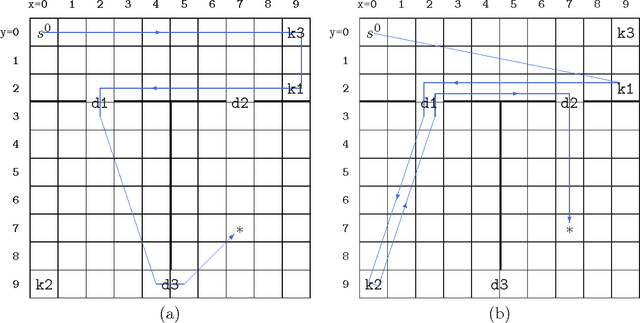


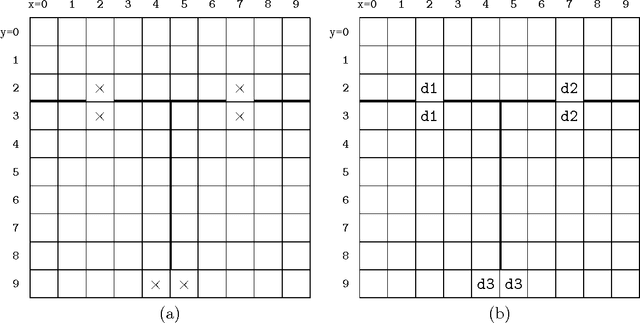
In a deterministic world, a planning agent can be certain of the consequences of its planned sequence of actions. Not so, however, in dynamic, stochastic domains where Markov decision processes are commonly used. Unfortunately these suffer from the curse of dimensionality: if the state space is a Cartesian product of many small sets (dimensions), planning is exponential in the number of those dimensions. Our new technique exploits the intuitive strategy of selectively ignoring various dimensions in different parts of the state space. The resulting non-uniformity has strong implications, since the approximation is no longer Markovian, requiring the use of a modified planner. We also use a spatial and temporal proximity measure, which responds to continued planning as well as movement of the agent through the state space, to dynamically adapt the abstraction as planning progresses. We present qualitative and quantitative results across a range of experimental domains showing that an agent exploiting this novel approximation method successfully finds solutions to the planning problem using much less than the full state space. We assess and analyse the features of domains which our method can exploit.