 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOReole-FM: successes and challenges toward billion-parameter foundation models for high-resolution satellite imagery
Oct 25, 2024While the pretraining of Foundation Models (FMs) for remote sensing (RS) imagery is on the rise, models remain restricted to a few hundred million parameters. Scaling models to billions of parameters has been shown to yield unprecedented benefits including emergent abilities, but requires data scaling and computing resources typically not available outside industry R&D labs. In this work, we pair high-performance computing resources including Frontier supercomputer, America's first exascale system, and high-resolution optical RS data to pretrain billion-scale FMs. Our study assesses performance of different pretrained variants of vision Transformers across image classification, semantic segmentation and object detection benchmarks, which highlight the importance of data scaling for effective model scaling. Moreover, we discuss construction of a novel TIU pretraining dataset, model initialization, with data and pretrained models intended for public release. By discussing technical challenges and details often lacking in the related literature, this work is intended to offer best practices to the geospatial community toward efficient training and benchmarking of larger FMs.
Pretraining Billion-scale Geospatial Foundational Models on Frontier
Apr 17, 2024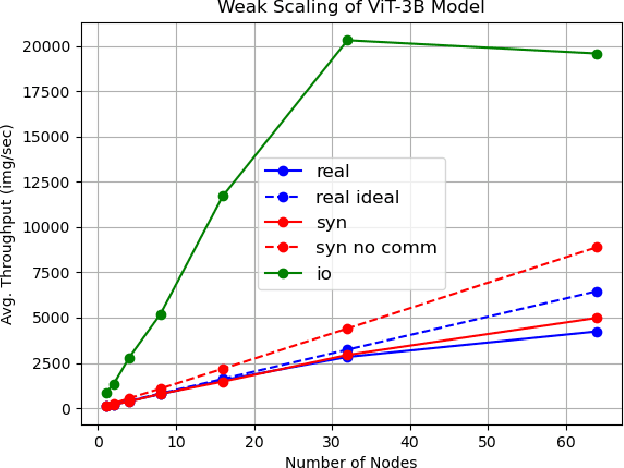
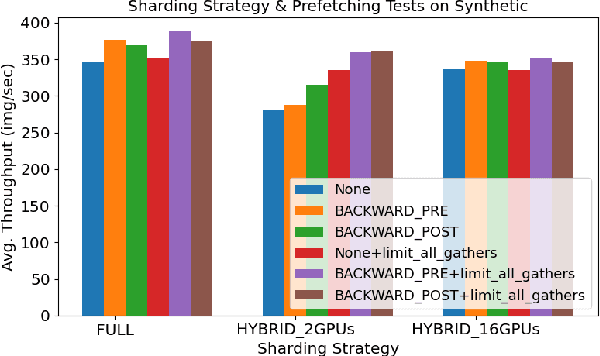
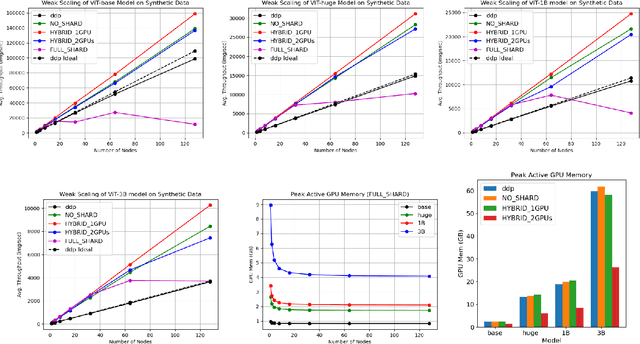
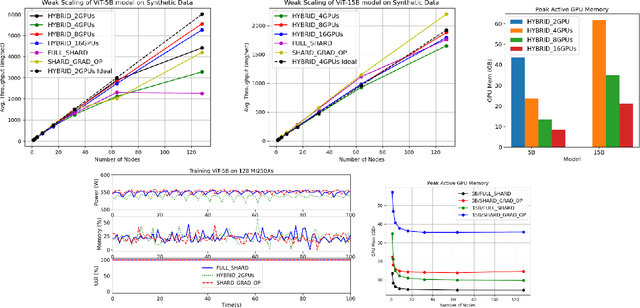
As AI workloads increase in scope, generalization capability becomes challenging for small task-specific models and their demand for large amounts of labeled training samples increases. On the contrary, Foundation Models (FMs) are trained with internet-scale unlabeled data via self-supervised learning and have been shown to adapt to various tasks with minimal fine-tuning. Although large FMs have demonstrated significant impact in natural language processing and computer vision, efforts toward FMs for geospatial applications have been restricted to smaller size models, as pretraining larger models requires very large computing resources equipped with state-of-the-art hardware accelerators. Current satellite constellations collect 100+TBs of data a day, resulting in images that are billions of pixels and multimodal in nature. Such geospatial data poses unique challenges opening up new opportunities to develop FMs. We investigate billion scale FMs and HPC training profiles for geospatial applications by pretraining on publicly available data. We studied from end-to-end the performance and impact in the solution by scaling the model size. Our larger 3B parameter size model achieves up to 30% improvement in top1 scene classification accuracy when comparing a 100M parameter model. Moreover, we detail performance experiments on the Frontier supercomputer, America's first exascale system, where we study different model and data parallel approaches using PyTorch's Fully Sharded Data Parallel library. Specifically, we study variants of the Vision Transformer architecture (ViT), conducting performance analysis for ViT models with size up to 15B parameters. By discussing throughput and performance bottlenecks under different parallelism configurations, we offer insights on how to leverage such leadership-class HPC resources when developing large models for geospatial imagery applications.