 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Centric Approach to Detecting and Mitigating Demographic Bias in Pediatric Mental Health Text: A Case Study in Anxiety Detection
Dec 30, 2024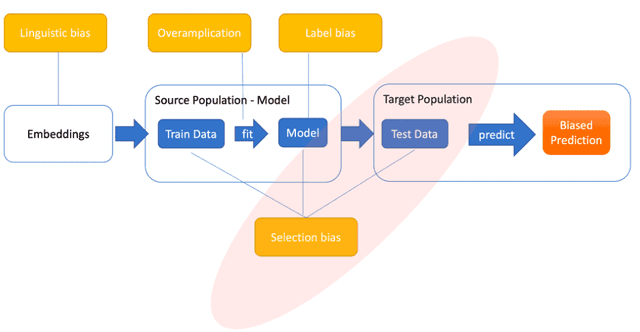
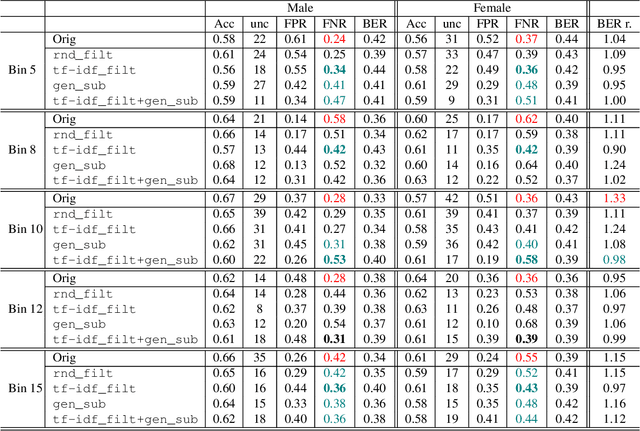
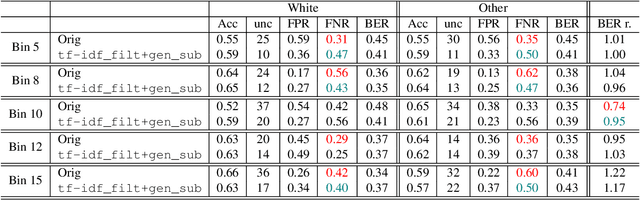
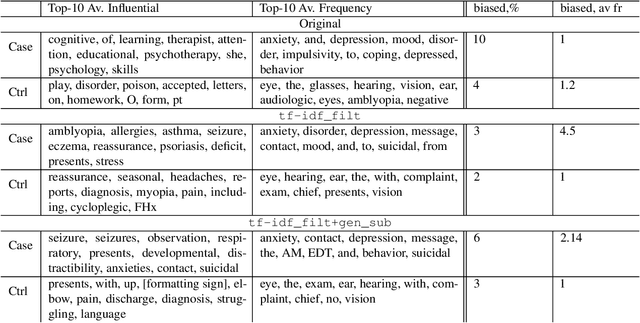
Introduction: Healthcare AI models often inherit biases from their training data. While efforts have primarily targeted bias in structured data, mental health heavily depends on unstructured data. This study aims to detect and mitigate linguistic differences related to non-biological differences in the training data of AI models designed to assist in pediatric mental health screening. Our objectives are: (1) to assess the presence of bias by evaluating outcome parity across sex subgroups, (2) to identify bias sources through textual distribution analysis, and (3) to develop a de-biasing method for mental health text data. Methods: We examined classification parity across demographic groups and assessed how gendered language influences model predictions. A data-centric de-biasing method was applied, focusing on neutralizing biased terms while retaining salient clinical information. This methodology was tested on a model for automatic anxiety detection in pediatric patients. Results: Our findings revealed a systematic under-diagnosis of female adolescent patients, with a 4% lower accuracy and a 9% higher False Negative Rate (FNR) compared to male patients, likely due to disparities in information density and linguistic differences in patient notes. Notes for male patients were on average 500 words longer, and linguistic similarity metrics indicated distinct word distributions between genders. Implementing our de-biasing approach reduced diagnostic bias by up to 27%, demonstrating its effectiveness in enhancing equity across demographic groups. Discussion: We developed a data-centric de-biasing framework to address gender-based content disparities within clinical text. By neutralizing biased language and enhancing focus on clinically essential information, our approach demonstrates an effective strategy for mitigating bias in AI healthcare models trained on text.
Domain Shift Analysis in Chest Radiographs Classification in a Veterans Healthcare Administration Population
Jul 30, 2024



Objectives: This study aims to assess the impact of domain shift on chest X-ray classification accuracy and to analyze the influence of ground truth label quality and demographic factors such as age group, sex, and study year. Materials and Methods: We used a DenseNet121 model pretrained MIMIC-CXR dataset for deep learning-based multilabel classification using ground truth labels from radiology reports extracted using the CheXpert and CheXbert Labeler. We compared the performance of the 14 chest X-ray labels on the MIMIC-CXR and Veterans Healthcare Administration chest X-ray dataset (VA-CXR). The VA-CXR dataset comprises over 259k chest X-ray images spanning between the years 2010 and 2022. Results: The validation of ground truth and the assessment of multi-label classification performance across various NLP extraction tools revealed that the VA-CXR dataset exhibited lower disagreement rates than the MIMIC-CXR datasets. Additionally, there were notable differences in AUC scores between models utilizing CheXpert and CheXbert. When evaluating multi-label classification performance across different datasets, minimal domain shift was observed in unseen datasets, except for the label "Enlarged Cardiomediastinum." The study year's subgroup analyses exhibited the most significant variations in multi-label classification model performance. These findings underscore the importance of considering domain shifts in chest X-ray classification tasks, particularly concerning study years. Conclusion: Our study reveals the significant impact of domain shift and demographic factors on chest X-ray classification, emphasizing the need for improved transfer learning and equitable model development. Addressing these challenges is crucial for advancing medical imaging and enhancing patient care.
CRL: Class Representative Learning for Image Classification
Feb 16, 2020
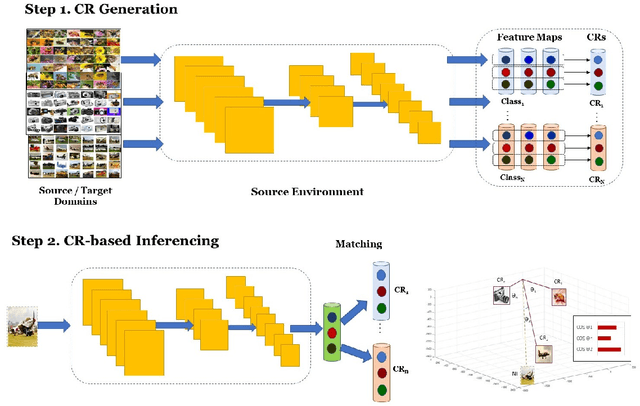


Building robust and real-time classifiers with diverse datasets are one of the most significant challenges to deep learning researchers. It is because there is a considerable gap between a model built with training (seen) data and real (unseen) data in applications. Recent works including Zero-Shot Learning (ZSL), have attempted to deal with this problem of overcoming the apparent gap through transfer learning. In this paper, we propose a novel model, called Class Representative Learning Model (CRL), that can be especially effective in image classification influenced by ZSL. In the CRL model, first, the learning step is to build class representatives to represent classes in datasets by aggregating prominent features extracted from a Convolutional Neural Network (CNN). Second, the inferencing step in CRL is to match between the class representatives and new data. The proposed CRL model demonstrated superior performance compared to the current state-of-the-art research in ZSL and mobile deep learning. The proposed CRL model has been implemented and evaluated in a parallel environment, using Apache Spark, for both distributed learning and recognition. An extensive experimental study on the benchmark datasets, ImageNet-1K, CalTech-101, CalTech-256, CIFAR-100, shows that CRL can build a class distribution model with drastic improvement in learning and recognition performance without sacrificing accuracy compared to the state-of-the-art performances in image classification.