 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Centric Approach to Detecting and Mitigating Demographic Bias in Pediatric Mental Health Text: A Case Study in Anxiety Detection
Dec 30, 2024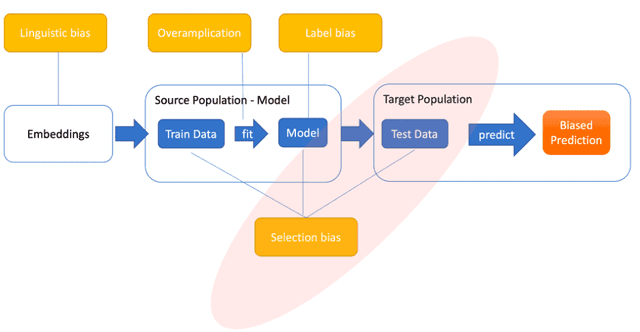
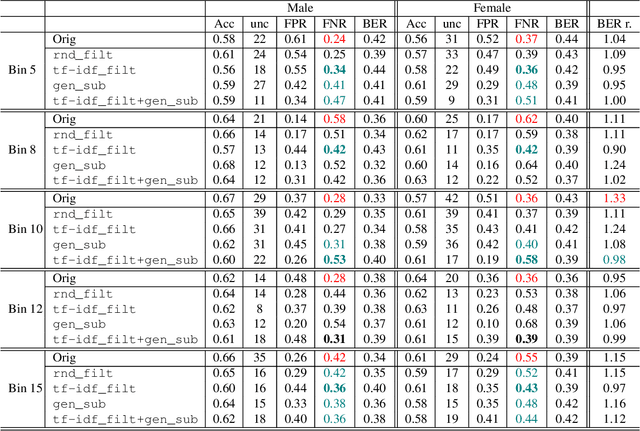
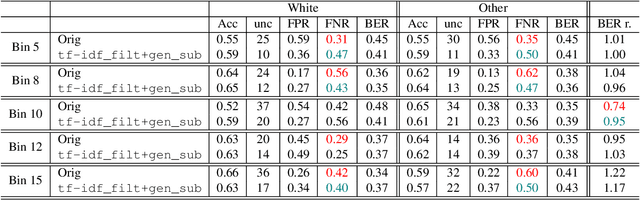
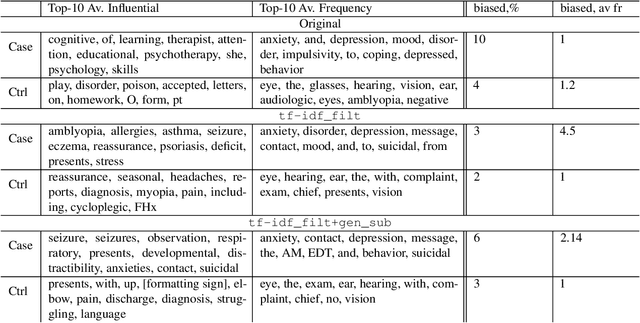
Introduction: Healthcare AI models often inherit biases from their training data. While efforts have primarily targeted bias in structured data, mental health heavily depends on unstructured data. This study aims to detect and mitigate linguistic differences related to non-biological differences in the training data of AI models designed to assist in pediatric mental health screening. Our objectives are: (1) to assess the presence of bias by evaluating outcome parity across sex subgroups, (2) to identify bias sources through textual distribution analysis, and (3) to develop a de-biasing method for mental health text data. Methods: We examined classification parity across demographic groups and assessed how gendered language influences model predictions. A data-centric de-biasing method was applied, focusing on neutralizing biased terms while retaining salient clinical information. This methodology was tested on a model for automatic anxiety detection in pediatric patients. Results: Our findings revealed a systematic under-diagnosis of female adolescent patients, with a 4% lower accuracy and a 9% higher False Negative Rate (FNR) compared to male patients, likely due to disparities in information density and linguistic differences in patient notes. Notes for male patients were on average 500 words longer, and linguistic similarity metrics indicated distinct word distributions between genders. Implementing our de-biasing approach reduced diagnostic bias by up to 27%, demonstrating its effectiveness in enhancing equity across demographic groups. Discussion: We developed a data-centric de-biasing framework to address gender-based content disparities within clinical text. By neutralizing biased language and enhancing focus on clinically essential information, our approach demonstrates an effective strategy for mitigating bias in AI healthcare models trained on text.
LISR: Learning Linear 3D Implicit Surface Representation Using Compactly Supported Radial Basis Functions
Feb 11, 2024Implicit 3D surface reconstruction of an object from its partial and noisy 3D point cloud scan is the classical geometry processing and 3D computer vision problem. In the literature, various 3D shape representations have been developed, differing in memory efficiency and shape retrieval effectiveness, such as volumetric, parametric, and implicit surfaces. Radial basis functions provide memory-efficient parameterization of the implicit surface. However, we show that training a neural network using the mean squared error between the ground-truth implicit surface and the linear basis-based implicit surfaces does not converge to the global solution. In this work, we propose locally supported compact radial basis functions for a linear representation of the implicit surface. This representation enables us to generate 3D shapes with arbitrary topologies at any resolution due to their continuous nature. We then propose a neural network architecture for learning the linear implicit shape representation of the 3D surface of an object. We learn linear implicit shapes within a supervised learning framework using ground truth Signed-Distance Field (SDF) data for guidance. The classical strategies face difficulties in finding linear implicit shapes from a given 3D point cloud due to numerical issues (requires solving inverse of a large matrix) in basis and query point selection. The proposed approach achieves better Chamfer distance and comparable F-score than the state-of-the-art approach on the benchmark dataset. We also show the effectiveness of the proposed approach by using it for the 3D shape completion task.