 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioADAPT-MRC: Adversarial Learning-based Domain Adaptation Improves Biomedical Machine Reading Comprehension Task
Paper and Code
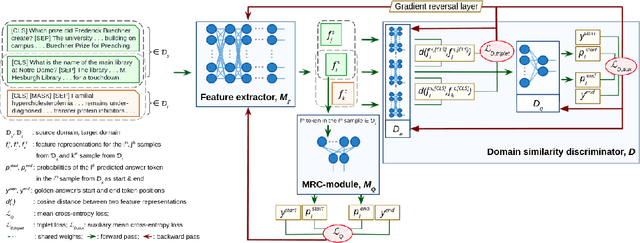

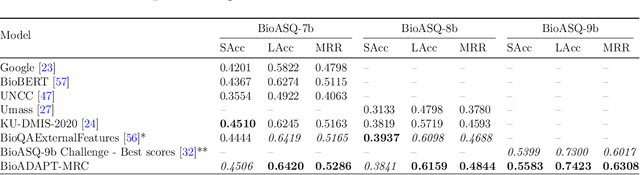
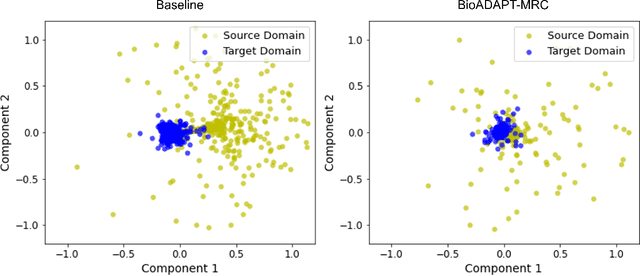
Motivation: Biomedical machine reading comprehension (biomedical-MRC) aims to comprehend complex biomedical narratives and assist healthcare professionals in retrieving information from them. The high performance of modern neural network-based MRC systems depends on high-quality, large-scale, human-annotated training datasets. In the biomedical domain, a crucial challenge in creating such datasets is the requirement for domain knowledge, inducing the scarcity of labeled data and the need for transfer learning from the labeled general-purpose (source) domain to the biomedical (target) domain. However, there is a discrepancy in marginal distributions between the general-purpose and biomedical domains due to the variances in topics. Therefore, direct-transferring of learned representations from a model trained on a general-purpose domain to the biomedical domain can hurt the model's performance. Results: We present an adversarial learning-based domain adaptation framework for the biomedical machine reading comprehension task (BioADAPT-MRC), a neural network-based method to address the discrepancies in the marginal distributions between the general and biomedical domain datasets. BioADAPT-MRC relaxes the need for generating pseudo labels for training a well-performing biomedical-MRC model. We extensively evaluate the performance of BioADAPT-MRC by comparing it with the best existing methods on three widely used benchmark biomedical-MRC datasets -- BioASQ-7b, BioASQ-8b, and BioASQ-9b. Our results suggest that without using any synthetic or human-annotated data from the biomedical domain, BioADAPT-MRC can achieve state-of-the-art performance on these datasets. Availability: BioADAPT-MRC is freely available as an open-source project at\\https://github.com/mmahbub/BioADAPT-MRC