 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sensitivity of Word Embeddings-based Author Detection Models to Semantic-preserving Adversarial Perturbations
Feb 23, 2021

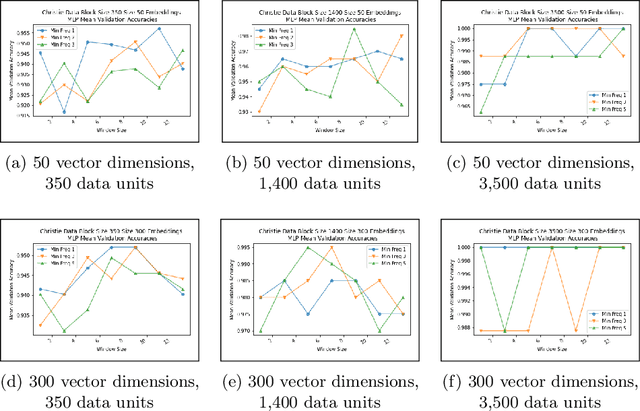

Authorship analysis is an important subject in the field of natural language processing. It allows the detection of the most likely writer of articles, news, books, or messages. This technique has multiple uses in tasks related to authorship attribution, detection of plagiarism, style analysis, sources of misinformation, etc. The focus of this paper is to explore the limitations and sensitiveness of established approaches to adversarial manipulations of inputs. To this end, and using those established techniques, we first developed an experimental frame-work for author detection and input perturbations. Next, we experimentally evaluated the performance of the authorship detection model to a collection of semantic-preserving adversarial perturbations of input narratives. Finally, we compare and analyze the effects of different perturbation strategies, input and model configurations, and the effects of these on the author detection model.
Scalable Dynamic Topic Modeling with Clustered Latent Dirichlet Allocation (CLDA)
Oct 15, 2017
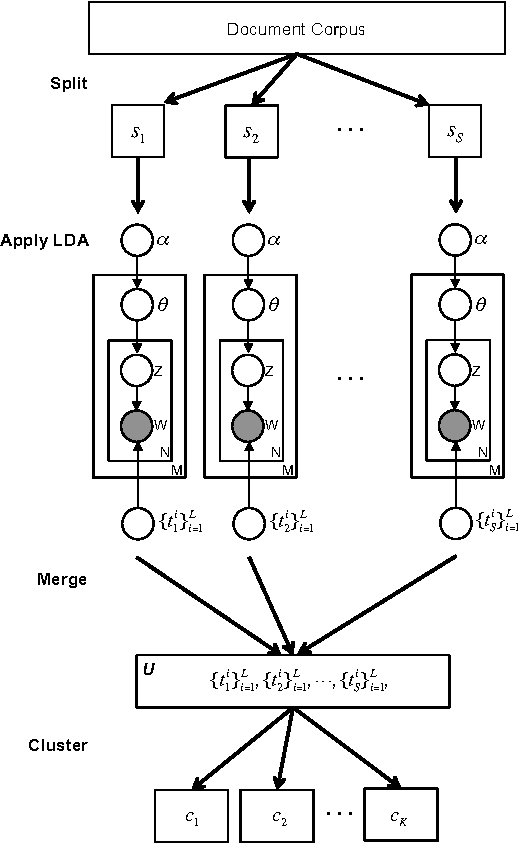
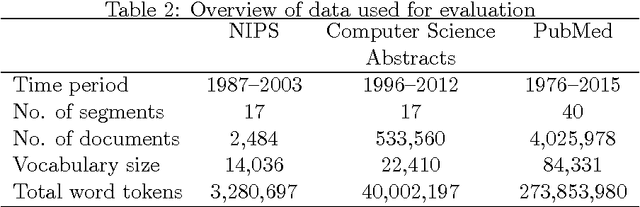
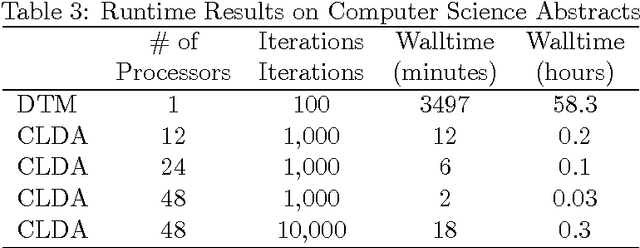
Topic modeling, a method for extracting the underlying themes from a collection of documents, is an increasingly important component of the design of intelligent systems enabling the sense-making of highly dynamic and diverse streams of text data. Traditional methods such as Dynamic Topic Modeling (DTM) do not lend themselves well to direct parallelization because of dependencies from one time step to another. In this paper, we introduce and empirically analyze Clustered Latent Dirichlet Allocation (CLDA), a method for extracting dynamic latent topics from a collection of documents. Our approach is based on data decomposition in which the data is partitioned into segments, followed by topic modeling on the individual segments. The resulting local models are then combined into a global solution using clustering. The decomposition and resulting parallelization leads to very fast runtime even on very large datasets. Our approach furthermore provides insight into how the composition of topics changes over time and can also be applied using other data partitioning strategies over any discrete features of the data, such as geographic features or classes of users. In this paper CLDA is applied successfully to seventeen years of NIPS conference papers (2,484 documents and 3,280,697 words), seventeen years of computer science journal abstracts (533,560 documents and 32,551,540 words), and to forty years of the PubMed corpus (4,025,978 documents and 273,853,980 words).