 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRED: Flexible REduction-Distribution Interconnect and Communication Implementation for Wafer-Scale Distributed Training of DNN Models
Jun 28, 2024



Distributed Deep Neural Network (DNN) training is a technique to reduce the training overhead by distributing the training tasks into multiple accelerators, according to a parallelization strategy. However, high-performance compute and interconnects are needed for maximum speed-up and linear scaling of the system. Wafer-scale systems are a promising technology that allows for tightly integrating high-end accelerators with high-speed wafer-scale interconnects, making it an attractive platform for distributed training. However, the wafer-scale interconnect should offer high performance and flexibility for various parallelization strategies to enable maximum optimizations for compute and memory usage. In this paper, we propose FRED, a wafer-scale interconnect that is tailored for the high-BW requirements of wafer-scale networks and can efficiently execute communication patterns of different parallelization strategies. Furthermore, FRED supports in-switch collective communication execution that reduces the network traffic by approximately 2X. Our results show that FRED can improve the average end-to-end training time of ResNet-152, Transformer-17B, GPT-3, and Transformer-1T by 1.76X, 1.87X, 1.34X, and 1.4X, respectively when compared to a baseline waferscale 2D-Mesh fabric.
Chakra: Advancing Performance Benchmarking and Co-design using Standardized Execution Traces
May 26, 2023



Benchmarking and co-design are essential for driving optimizations and innovation around ML models, ML software, and next-generation hardware. Full workload benchmarks, e.g. MLPerf, play an essential role in enabling fair comparison across different software and hardware stacks especially once systems are fully designed and deployed. However, the pace of AI innovation demands a more agile methodology to benchmark creation and usage by simulators and emulators for future system co-design. We propose Chakra, an open graph schema for standardizing workload specification capturing key operations and dependencies, also known as Execution Trace (ET). In addition, we propose a complementary set of tools/capabilities to enable collection, generation, and adoption of Chakra ETs by a wide range of simulators, emulators, and benchmarks. For instance, we use generative AI models to learn latent statistical properties across thousands of Chakra ETs and use these models to synthesize Chakra ETs. These synthetic ETs can obfuscate key proprietary information and also target future what-if scenarios. As an example, we demonstrate an end-to-end proof-of-concept that converts PyTorch ETs to Chakra ETs and uses this to drive an open-source training system simulator (ASTRA-sim). Our end-goal is to build a vibrant industry-wide ecosystem of agile benchmarks and tools to drive future AI system co-design.
ASTRA-sim2.0: Modeling Hierarchical Networks and Disaggregated Systems for Large-model Training at Scale
Mar 24, 2023As deep learning models and input data are scaling at an unprecedented rate, it is inevitable to move towards distributed training platforms to fit the model and increase training throughput. State-of-the-art approaches and techniques, such as wafer-scale nodes, multi-dimensional network topologies, disaggregated memory systems, and parallelization strategies, have been actively adopted by emerging distributed training systems. This results in a complex SW/HW co-design stack of distributed training, necessitating a modeling/simulation infrastructure for design-space exploration. In this paper, we extend the open-source ASTRA-sim infrastructure and endow it with the capabilities to model state-of-the-art and emerging distributed training models and platforms. More specifically, (i) we enable ASTRA-sim to support arbitrary model parallelization strategies via a graph-based training-loop implementation, (ii) we implement a parameterizable multi-dimensional heterogeneous topology generation infrastructure with analytical performance estimates enabling simulating target systems at scale, and (iii) we enhance the memory system modeling to support accurate modeling of in-network collective communication and disaggregated memory systems. With such capabilities, we run comprehensive case studies targeting emerging distributed models and platforms. This infrastructure lets system designers swiftly traverse the complex co-design stack and give meaningful insights when designing and deploying distributed training platforms at scale.
COMET: A Comprehensive Cluster Design Methodology for Distributed Deep Learning Training
Nov 30, 2022Modern Deep Learning (DL) models have grown to sizes requiring massive clusters of specialized, high-end nodes to train. Designing such clusters to maximize both performance and utilization to amortize their steep cost is a challenging task requiring careful balance of compute, memory, and network resources. Moreover, a plethora of each model's tuning knobs drastically affect the performance, with optimal values often depending on the underlying cluster's characteristics, which necessitates a complex cluster-workload co-design process. To facilitate the design space exploration of such massive DL training clusters, we introduce COMET a holistic cluster design methodology and workflow to jointly study the impact of parallelization strategies and key cluster resource provisioning on the performance of distributed DL training. We develop a step-by-step process to establish a reusable and flexible methodology, and demonstrate its application with a case study of training a Transformer-1T model on a cluster of variable compute, memory, and network resources. Our case study demonstrates COMET's utility in identifying promising architectural optimization directions and guiding system designers in configuring key model and cluster parameters.
Impact of RoCE Congestion Control Policies on Distributed Training of DNNs
Jul 22, 2022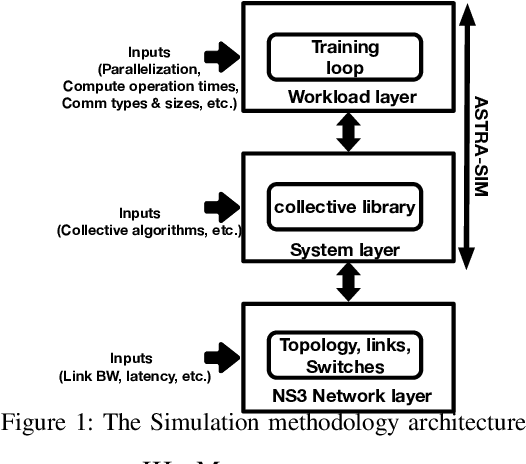
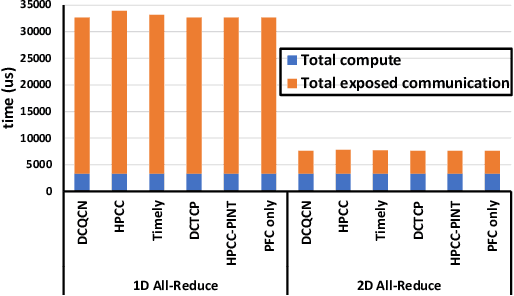
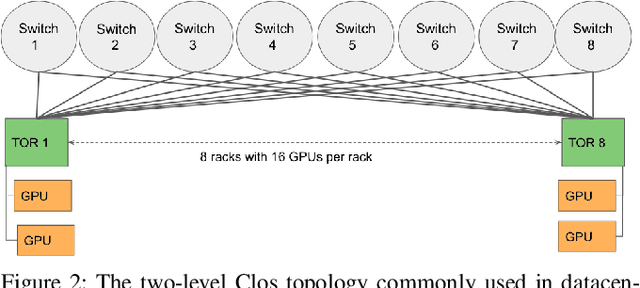
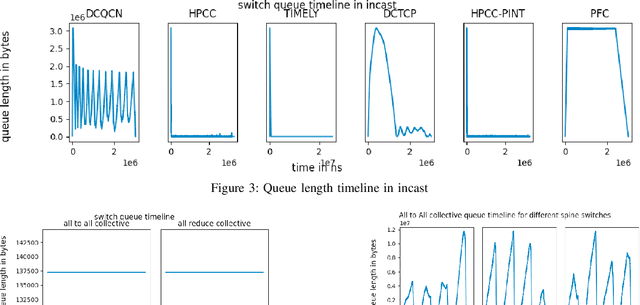
RDMA over Converged Ethernet (RoCE) has gained significant attraction for datacenter networks due to its compatibility with conventional Ethernet-based fabric. However, the RDMA protocol is efficient only on (nearly) lossless networks, emphasizing the vital role of congestion control on RoCE networks. Unfortunately, the native RoCE congestion control scheme, based on Priority Flow Control (PFC), suffers from many drawbacks such as unfairness, head-of-line-blocking, and deadlock. Therefore, in recent years many schemes have been proposed to provide additional congestion control for RoCE networks to minimize PFC drawbacks. However, these schemes are proposed for general datacenter environments. In contrast to the general datacenters that are built using commodity hardware and run general-purpose workloads, high-performance distributed training platforms deploy high-end accelerators and network components and exclusively run training workloads using collectives (All-Reduce, All-To-All) communication libraries for communication. Furthermore, these platforms usually have a private network, separating their communication traffic from the rest of the datacenter traffic. Scalable topology-aware collective algorithms are inherently designed to avoid incast patterns and balance traffic optimally. These distinct features necessitate revisiting previously proposed congestion control schemes for general-purpose datacenter environments. In this paper, we thoroughly analyze some of the SOTA RoCE congestion control schemes vs. PFC when running on distributed training platforms. Our results indicate that previously proposed RoCE congestion control schemes have little impact on the end-to-end performance of training workloads, motivating the necessity of designing an optimized, yet low-overhead, congestion control scheme based on the characteristics of distributed training platforms and workloads.
Themis: A Network Bandwidth-Aware Collective Scheduling Policy for Distributed Training of DL Models
Oct 09, 2021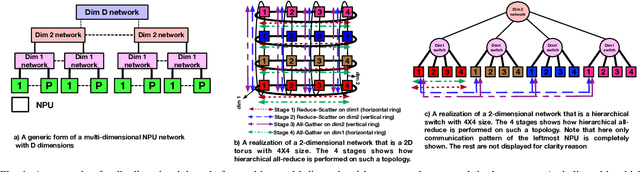



The continuous growth in both size and training data for modern Deep Neural Networks (DNNs) models has led to training tasks taking days or even months. Distributed training is a solution to reduce training time by splitting the task across multiple NPUs (e.g., GPU/TPU). However, distributed training adds communication overhead between the NPUs in order to synchronize the gradients and/or activation, depending on the parallelization strategy. In today's datacenters, for training at scale, NPUs are connected through multi-dimensional interconnection links with different bandwidth and latency. Hence, keeping all network dimensions busy and maximizing the network BW is a challenging task in such a hybrid network environment, as this work identifies. We propose Themis, a novel collective scheduling scheme that dynamically schedules collectives (divided into chunks) to balance the communication loads across all dimensions, further improving the network BW utilization. Our results show that on average, Themis can improve the network BW utilization of single All-Reduce by 1.88x (2.92x max), and improve the end-to-end training iteration performance of real workloads such as ResNet-50, GNMT, DLRM, and Transformer- 1T by 1.49x (1.96x max), 1.41x (1.81x max), 1.42x (1.80x max), and 1.35x (1.78x max), respectively.
Exploring Multi-dimensional Hierarchical Network Topologies for Efficient Distributed Training of Trillion Parameter DL Models
Sep 24, 2021

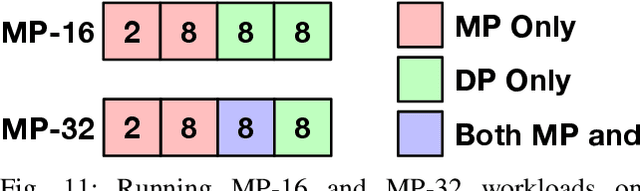

Deep Neural Networks have gained significant attraction due to their wide applicability in different domains. DNN sizes and training samples are constantly growing, making training of such workloads more challenging. Distributed training is a solution to reduce the training time. High-performance distributed training platforms should leverage multi-dimensional hierarchical networks, which interconnect accelerators through different levels of the network, to dramatically reduce expensive NICs required for the scale-out network. However, it comes at the expense of communication overhead between distributed accelerators to exchange gradients or input/output activation. In order to allow for further scaling of the workloads, communication overhead needs to be minimized. In this paper, we motivate the fact that in training platforms, adding more intermediate network dimensions is beneficial for efficiently mitigating the excessive use of expensive NIC resources. Further, we address different challenges of the DNN training on hierarchical networks. We discuss when designing the interconnect, how to distribute network bandwidth resources across different dimensions in order to (i) maximize BW utilization of all dimensions, and (ii) minimizing the overall training time for the target workload. We then implement a framework that, for a given workload, determines the best network configuration that maximizes performance, or performance-per-cost.
Restructuring, Pruning, and Adjustment of Deep Models for Parallel Distributed Inference
Aug 19, 2020

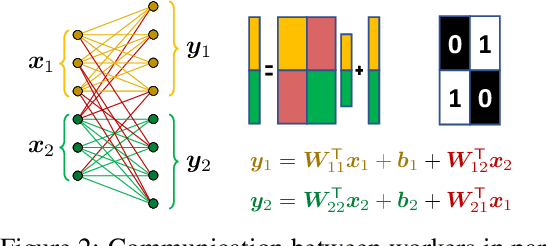

Using multiple nodes and parallel computing algorithms has become a principal tool to improve training and execution times of deep neural networks as well as effective collective intelligence in sensor networks. In this paper, we consider the parallel implementation of an already-trained deep model on multiple processing nodes (a.k.a. workers) where the deep model is divided into several parallel sub-models, each of which is executed by a worker. Since latency due to synchronization and data transfer among workers negatively impacts the performance of the parallel implementation, it is desirable to have minimum interdependency among parallel sub-models. To achieve this goal, we propose to rearrange the neurons in the neural network and partition them (without changing the general topology of the neural network), such that the interdependency among sub-models is minimized under the computations and communications constraints of the workers. We propose RePurpose, a layer-wise model restructuring and pruning technique that guarantees the performance of the overall parallelized model. To efficiently apply RePurpose, we propose an approach based on $\ell_0$ optimization and the Munkres assignment algorithm. We show that, compared to the existing methods, RePurpose significantly improves the efficiency of the distributed inference via parallel implementation, both in terms of communication and computational complexity.