 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThemis: A Network Bandwidth-Aware Collective Scheduling Policy for Distributed Training of DL Models
Paper and Code
Oct 09, 2021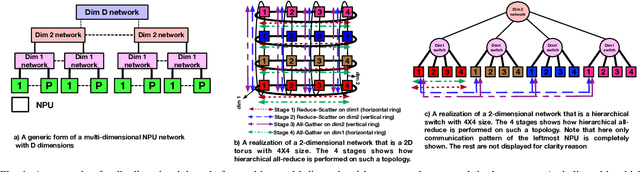



The continuous growth in both size and training data for modern Deep Neural Networks (DNNs) models has led to training tasks taking days or even months. Distributed training is a solution to reduce training time by splitting the task across multiple NPUs (e.g., GPU/TPU). However, distributed training adds communication overhead between the NPUs in order to synchronize the gradients and/or activation, depending on the parallelization strategy. In today's datacenters, for training at scale, NPUs are connected through multi-dimensional interconnection links with different bandwidth and latency. Hence, keeping all network dimensions busy and maximizing the network BW is a challenging task in such a hybrid network environment, as this work identifies. We propose Themis, a novel collective scheduling scheme that dynamically schedules collectives (divided into chunks) to balance the communication loads across all dimensions, further improving the network BW utilization. Our results show that on average, Themis can improve the network BW utilization of single All-Reduce by 1.88x (2.92x max), and improve the end-to-end training iteration performance of real workloads such as ResNet-50, GNMT, DLRM, and Transformer- 1T by 1.49x (1.96x max), 1.41x (1.81x max), 1.42x (1.80x max), and 1.35x (1.78x max), respectively.