 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestructuring, Pruning, and Adjustment of Deep Models for Parallel Distributed Inference
Paper and Code
Aug 19, 2020

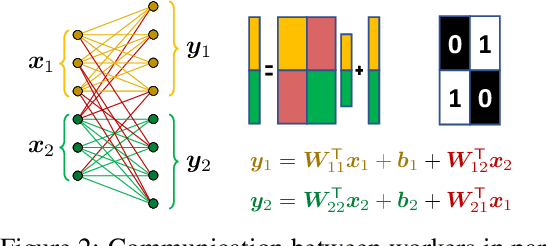

Using multiple nodes and parallel computing algorithms has become a principal tool to improve training and execution times of deep neural networks as well as effective collective intelligence in sensor networks. In this paper, we consider the parallel implementation of an already-trained deep model on multiple processing nodes (a.k.a. workers) where the deep model is divided into several parallel sub-models, each of which is executed by a worker. Since latency due to synchronization and data transfer among workers negatively impacts the performance of the parallel implementation, it is desirable to have minimum interdependency among parallel sub-models. To achieve this goal, we propose to rearrange the neurons in the neural network and partition them (without changing the general topology of the neural network), such that the interdependency among sub-models is minimized under the computations and communications constraints of the workers. We propose RePurpose, a layer-wise model restructuring and pruning technique that guarantees the performance of the overall parallelized model. To efficiently apply RePurpose, we propose an approach based on $\ell_0$ optimization and the Munkres assignment algorithm. We show that, compared to the existing methods, RePurpose significantly improves the efficiency of the distributed inference via parallel implementation, both in terms of communication and computational complexity.