 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystolic Computing on GPUs for Productive Performance
Oct 29, 2020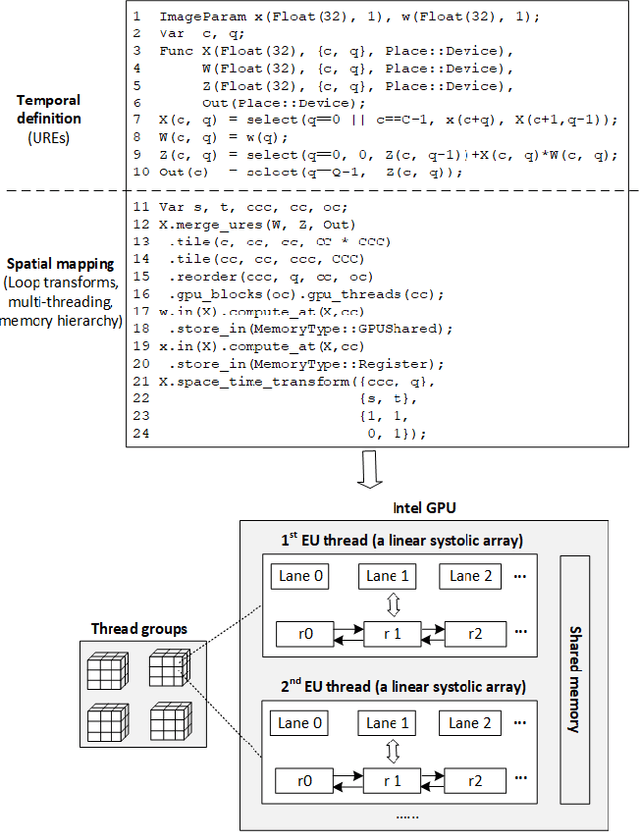
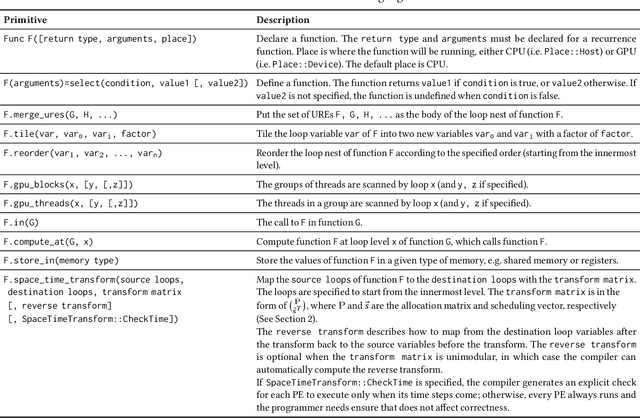
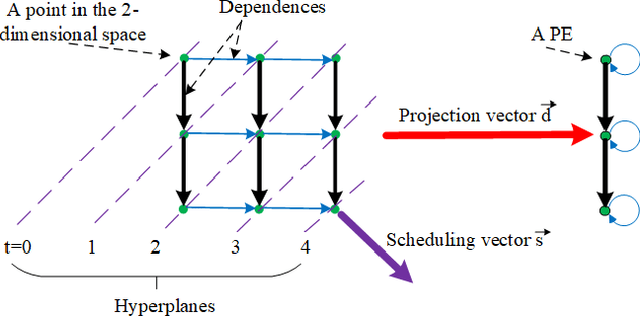
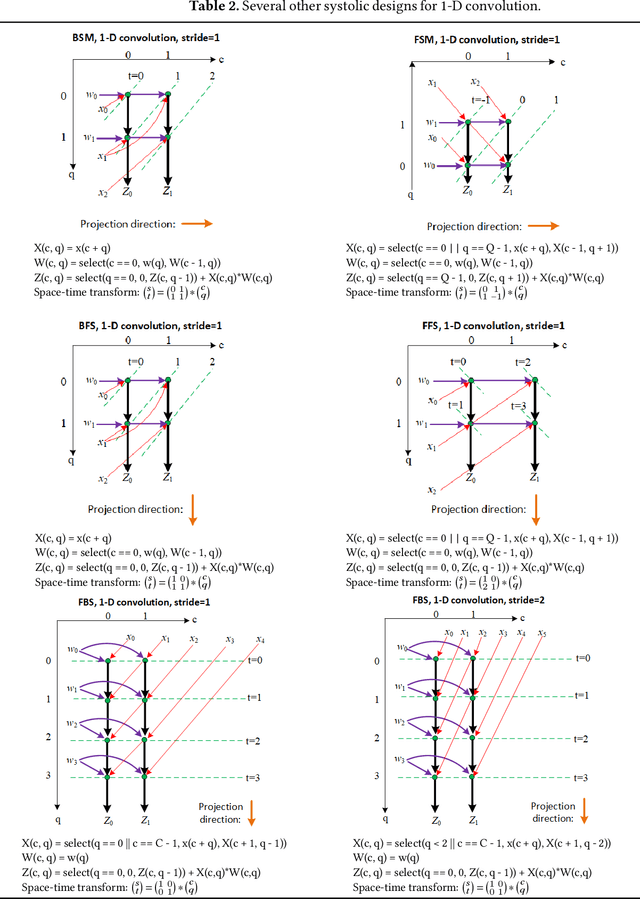
We propose a language and compiler to productively build high-performance {\it software systolic arrays} that run on GPUs. Based on a rigorous mathematical foundation (uniform recurrence equations and space-time transform), our language has a high abstraction level and covers a wide range of applications. A programmer {\it specifies} a projection of a dataflow compute onto a linear systolic array, while leaving the detailed implementation of the projection to a compiler; the compiler implements the specified projection and maps the linear systolic array to the SIMD execution units and vector registers of GPUs. In this way, both productivity and performance are achieved in the same time. This approach neatly combines loop transformations, data shuffling, and vector register allocation into a single framework. Meanwhile, many other optimizations can be applied as well; the compiler composes the optimizations together to generate efficient code. We implemented the approach on Intel GPUs. This is the first system that allows productive construction of systolic arrays on GPUs. We allow multiple projections, arbitrary projection directions and linear schedules, which can express most, if not all, systolic arrays in practice. Experiments with 1- and 2-D convolution on an Intel GEN9.5 GPU have demonstrated the generality of the approach, and its productivity in expressing various systolic designs for finding the best candidate. Although our systolic arrays are purely software running on generic SIMD hardware, compared with the GPU's specialized, hardware samplers that perform the same convolutions, some of our best designs are up to 59\% faster. Overall, this approach holds promise for productive high-performance computing on GPUs.