 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADaPTION: Toolbox and Benchmark for Training Convolutional Neural Networks with Reduced Numerical Precision Weights and Activation
Paper and Code
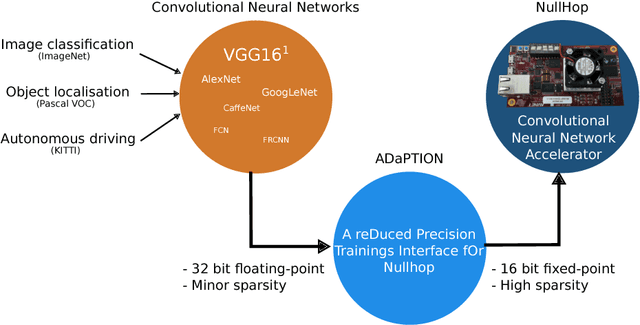
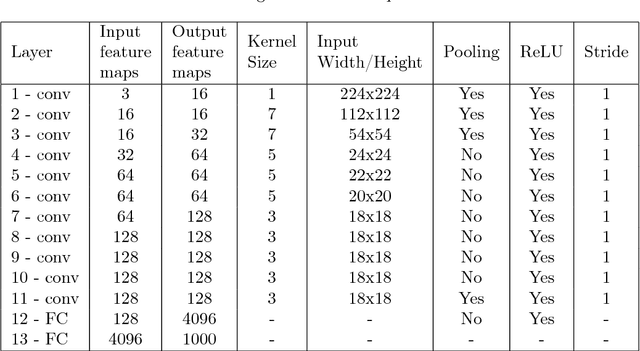
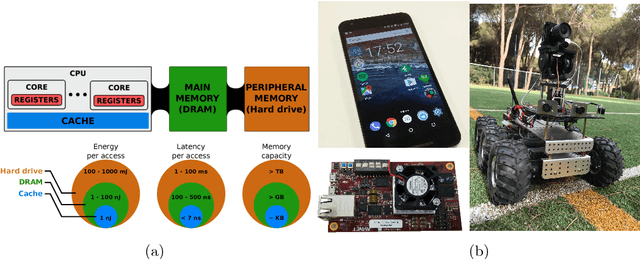
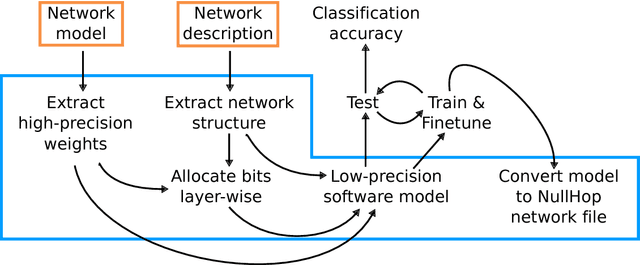
Deep Neural Networks (DNNs) and Convolutional Neural Networks (CNNs) are useful for many practical tasks in machine learning. Synaptic weights, as well as neuron activation functions within the deep network are typically stored with high-precision formats, e.g. 32 bit floating point. However, since storage capacity is limited and each memory access consumes power, both storage capacity and memory access are two crucial factors in these networks. Here we present a method and present the ADaPTION toolbox to extend the popular deep learning library Caffe to support training of deep CNNs with reduced numerical precision of weights and activations using fixed point notation. ADaPTION includes tools to measure the dynamic range of weights and activations. Using the ADaPTION tools, we quantized several CNNs including VGG16 down to 16-bit weights and activations with only 0.8% drop in Top-1 accuracy. The quantization, especially of the activations, leads to increase of up to 50% of sparsity especially in early and intermediate layers, which we exploit to skip multiplications with zero, thus performing faster and computationally cheaper inference.