 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNullHop: A Flexible Convolutional Neural Network Accelerator Based on Sparse Representations of Feature Maps
Mar 06, 2018
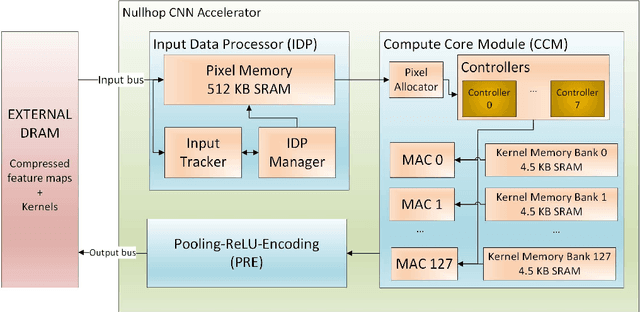
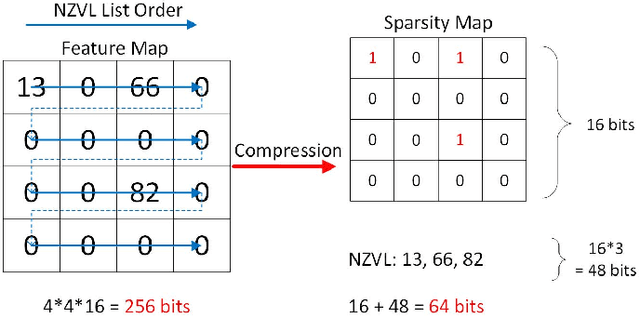
Convolutional neural networks (CNNs) have become the dominant neural network architecture for solving many state-of-the-art (SOA) visual processing tasks. Even though Graphical Processing Units (GPUs) are most often used in training and deploying CNNs, their power efficiency is less than 10 GOp/s/W for single-frame runtime inference. We propose a flexible and efficient CNN accelerator architecture called NullHop that implements SOA CNNs useful for low-power and low-latency application scenarios. NullHop exploits the sparsity of neuron activations in CNNs to accelerate the computation and reduce memory requirements. The flexible architecture allows high utilization of available computing resources across kernel sizes ranging from 1x1 to 7x7. NullHop can process up to 128 input and 128 output feature maps per layer in a single pass. We implemented the proposed architecture on a Xilinx Zynq FPGA platform and present results showing how our implementation reduces external memory transfers and compute time in five different CNNs ranging from small ones up to the widely known large VGG16 and VGG19 CNNs. Post-synthesis simulations using Mentor Modelsim in a 28nm process with a clock frequency of 500 MHz show that the VGG19 network achieves over 450 GOp/s. By exploiting sparsity, NullHop achieves an efficiency of 368%, maintains over 98% utilization of the MAC units, and achieves a power efficiency of over 3TOp/s/W in a core area of 6.3mm$^2$. As further proof of NullHop's usability, we interfaced its FPGA implementation with a neuromorphic event camera for real time interactive demonstrations.
ADaPTION: Toolbox and Benchmark for Training Convolutional Neural Networks with Reduced Numerical Precision Weights and Activation
Nov 13, 2017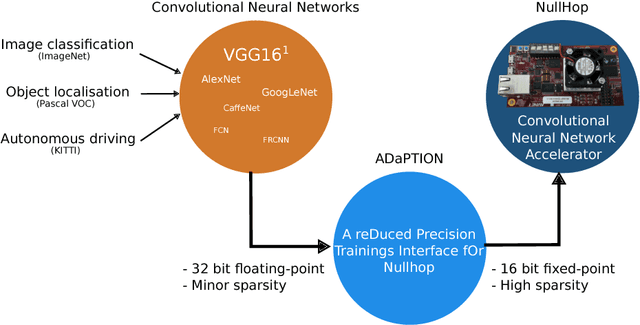
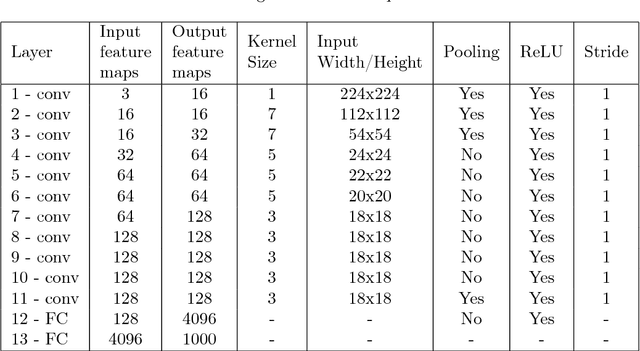
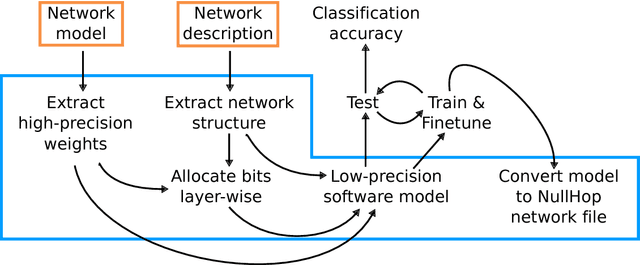
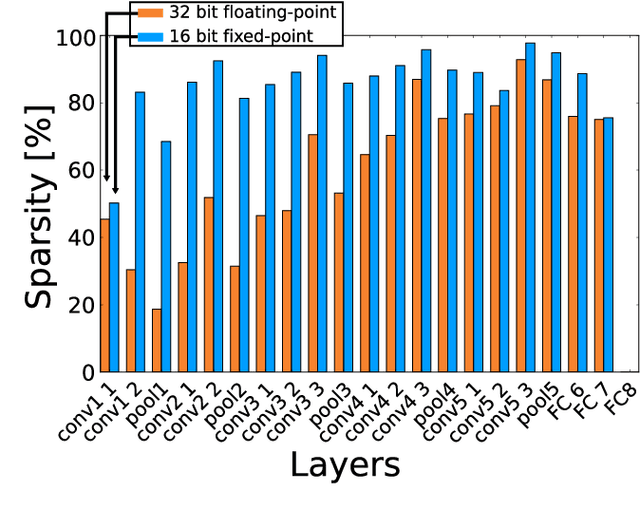
Deep Neural Networks (DNNs) and Convolutional Neural Networks (CNNs) are useful for many practical tasks in machine learning. Synaptic weights, as well as neuron activation functions within the deep network are typically stored with high-precision formats, e.g. 32 bit floating point. However, since storage capacity is limited and each memory access consumes power, both storage capacity and memory access are two crucial factors in these networks. Here we present a method and present the ADaPTION toolbox to extend the popular deep learning library Caffe to support training of deep CNNs with reduced numerical precision of weights and activations using fixed point notation. ADaPTION includes tools to measure the dynamic range of weights and activations. Using the ADaPTION tools, we quantized several CNNs including VGG16 down to 16-bit weights and activations with only 0.8% drop in Top-1 accuracy. The quantization, especially of the activations, leads to increase of up to 50% of sparsity especially in early and intermediate layers, which we exploit to skip multiplications with zero, thus performing faster and computationally cheaper inference.