 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining and inference in the ReckON RSNN architecture implemented on a MPSoC
May 21, 2024

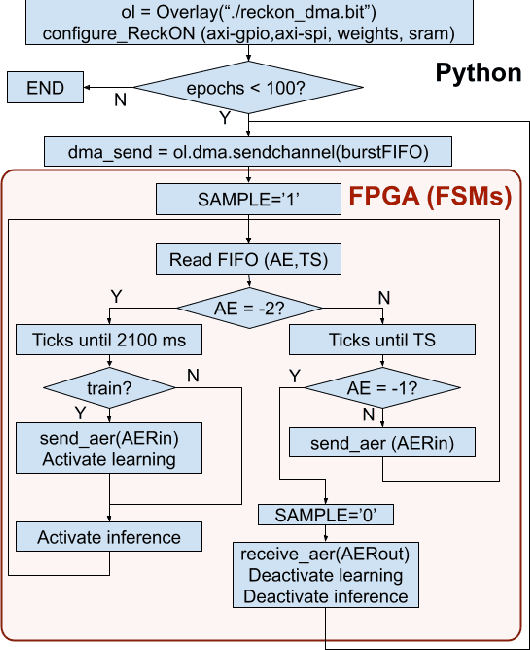

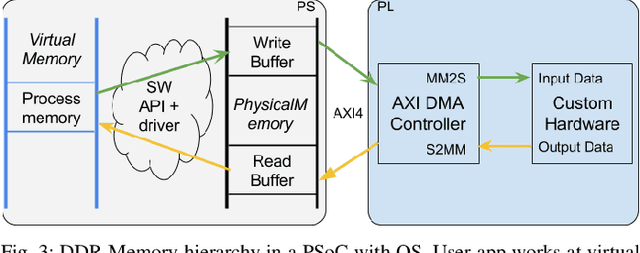
With the rise of artificial intelligence, biological neuron models are being used to implement neural networks that can learn certain tasks after a training phase. One type of such networks are spiking neural networks (SNNs) that rely on a simplified model for biological neurons, the Integrate and Fire neuron. Several accelerators have emerged to implement SNNs with this kind of neuron. The ReckON system is one of these that allows both the training and execution of a recurrent SNN. The ReckON architecture, implemented on a custom ASIC, can be fully described using a hardware description language. In this work, we adapt the Verilog description to implement it on a Xilinx Multiprocessor System on Chip system (MPSoC). We present the circuits required for the efficient operation of the system, and a Python framework to use it on the Pynq ZU platform. We validate the architecture and implementation in two different scenarios, and show how the simulated accuracy is preserved with a peak performance of 3.8M events processed per second.
LIPSFUS: A neuromorphic dataset for audio-visual sensory fusion of lip reading
Mar 28, 2023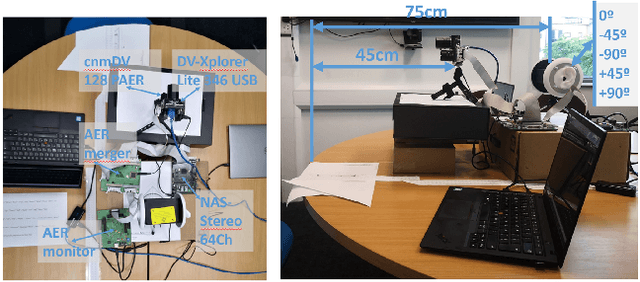
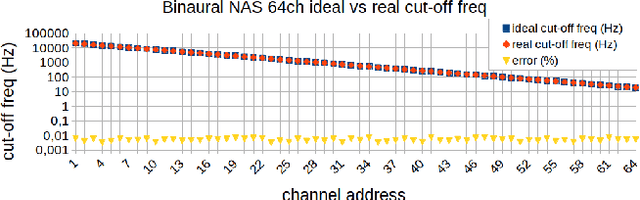
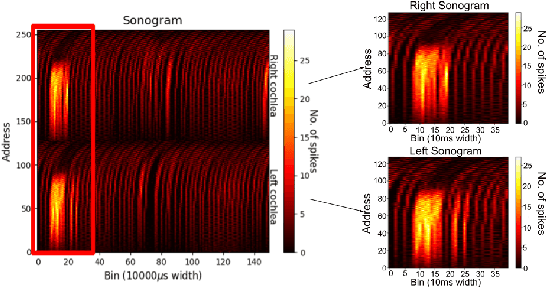
This paper presents a sensory fusion neuromorphic dataset collected with precise temporal synchronization using a set of Address-Event-Representation sensors and tools. The target application is the lip reading of several keywords for different machine learning applications, such as digits, robotic commands, and auxiliary rich phonetic short words. The dataset is enlarged with a spiking version of an audio-visual lip reading dataset collected with frame-based cameras. LIPSFUS is publicly available and it has been validated with a deep learning architecture for audio and visual classification. It is intended for sensory fusion architectures based on both artificial and spiking neural network algorithms.
An MPSoC-based on-line Edge Infrastructure for Embedded Neuromorphic Robotic Controllers
Mar 31, 2022
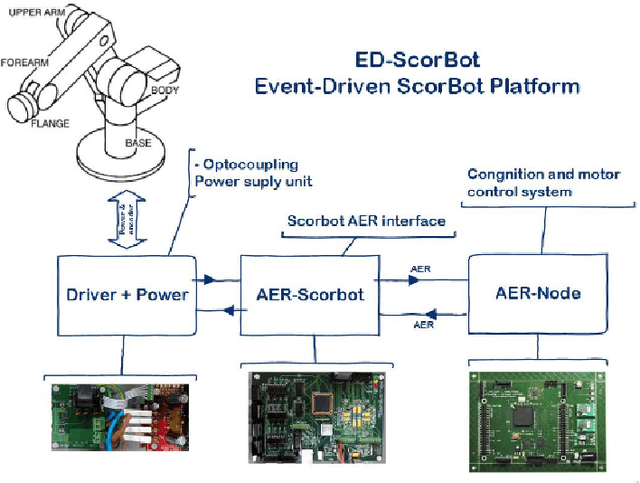


In this work, an all-in-one neuromorphic controller system with reduced latency and power consumption for a robotic arm is presented. Biological muscle movement consists of stretching and shrinking fibres via spike-commanded signals that come from motor neurons, which in turn are connected to a central pattern generator neural structure. In addition, biological systems are able to respond to diverse stimuli rather fast and efficiently, and this is based on the way information is coded within neural processes. As opposed to human-created encoding systems, neural ones use neurons and spikes to process the information and make weighted decisions based on a continuous learning process. The Event-Driven Scorbot platform (ED-Scorbot) consists of a 6 Degrees of Freedom (DoF) robotic arm whose controller implements a Spiking Proportional-Integrative- Derivative algorithm, mimicking in this way the previously commented biological systems. In this paper, we present an infrastructure upgrade to the ED-Scorbot platform, replacing the controller hardware, which was comprised of two Spartan Field Programmable Gate Arrays (FPGAs) and a barebone computer, with an edge device, the Xilinx Zynq-7000 SoC (System on Chip) which reduces the response time, power consumption and overall complexity.
Wide & Deep neural network model for patch aggregation in CNN-based prostate cancer detection systems
May 20, 2021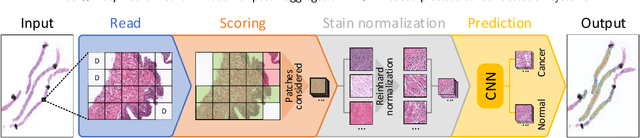
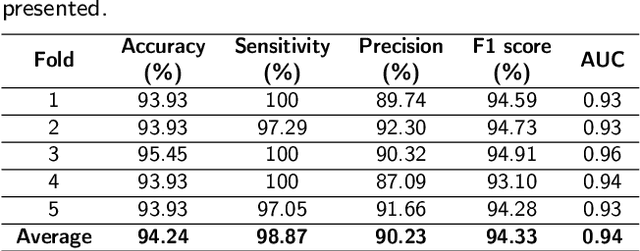
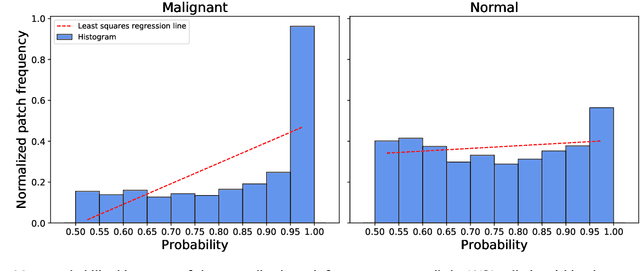
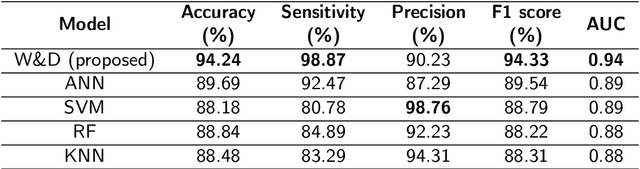
Prostate cancer (PCa) is one of the most commonly diagnosed cancer and one of the leading causes of death among men, with almost 1.41 million new cases and around 375,000 deaths in 2020. Artificial Intelligence algorithms have had a huge impact in medical image analysis, including digital histopathology, where Convolutional Neural Networks (CNNs) are used to provide a fast and accurate diagnosis, supporting experts in this task. To perform an automatic diagnosis, prostate tissue samples are first digitized into gigapixel-resolution whole-slide images. Due to the size of these images, neural networks cannot use them as input and, therefore, small subimages called patches are extracted and predicted, obtaining a patch-level classification. In this work, a novel patch aggregation method based on a custom Wide & Deep neural network model is presented, which performs a slide-level classification using the patch-level classes obtained from a CNN. The malignant tissue ratio, a 10-bin malignant probability histogram, the least squares regression line of the histogram, and the number of malignant connected components are used by the proposed model to perform the classification. An accuracy of 94.24% and a sensitivity of 98.87% were achieved, proving that the proposed system could aid pathologists by speeding up the screening process and, thus, contribute to the fight against PCa.
Dynamic Vision Sensor integration on FPGA-based CNN accelerators for high-speed visual classification
May 17, 2019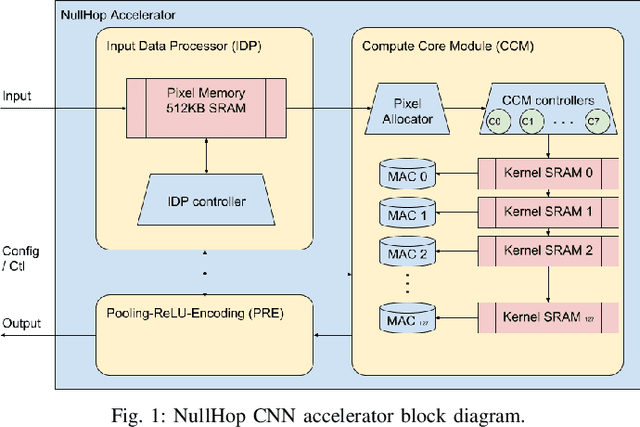
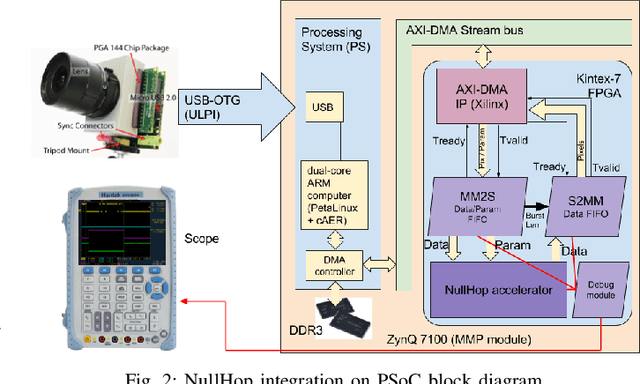
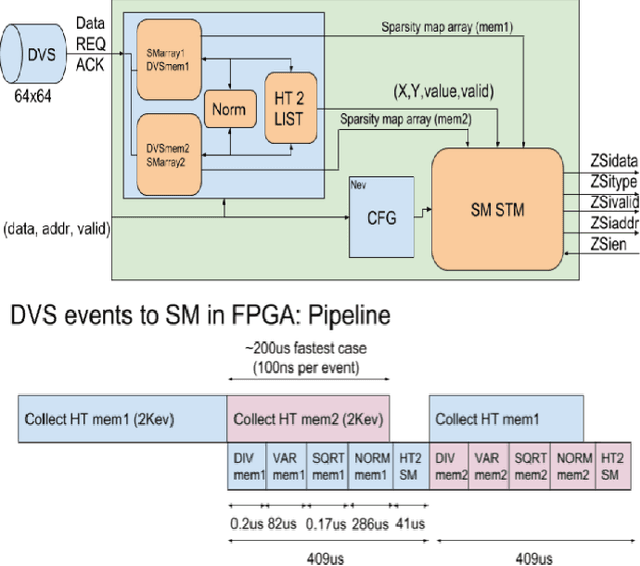
Deep-learning is a cutting edge theory that is being applied to many fields. For vision applications the Convolutional Neural Networks (CNN) are demanding significant accuracy for classification tasks. Numerous hardware accelerators have populated during the last years to improve CPU or GPU based solutions. This technology is commonly prototyped and tested over FPGAs before being considered for ASIC fabrication for mass production. The use of commercial typical cameras (30fps) limits the capabilities of these systems for high speed applications. The use of dynamic vision sensors (DVS) that emulate the behavior of a biological retina is taking an incremental importance to improve this applications due to its nature, where the information is represented by a continuous stream of spikes and the frames to be processed by the CNN are constructed collecting a fixed number of these spikes (called events). The faster an object is, the more events are produced by DVS, so the higher is the equivalent frame rate. Therefore, these DVS utilization allows to compute a frame at the maximum speed a CNN accelerator can offer. In this paper we present a VHDL/HLS description of a pipelined design for FPGA able to collect events from an Address-Event-Representation (AER) DVS retina to obtain a normalized histogram to be used by a particular CNN accelerator, called NullHop. VHDL is used to describe the circuit, and HLS for computation blocks, which are used to perform the normalization of a frame needed for the CNN. Results outperform previous implementations of frames collection and normalization using ARM processors running at 800MHz on a Zynq7100 in both latency and power consumption. A measured 67% speedup factor is presented for a Roshambo CNN real-time experiment running at 160fps peak rate.
NeuroPod: a real-time neuromorphic spiking CPG applied to robotics
Apr 25, 2019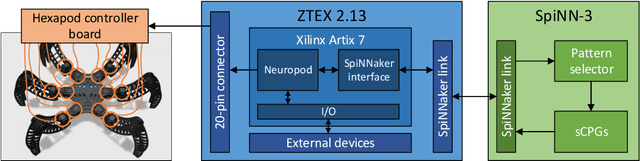

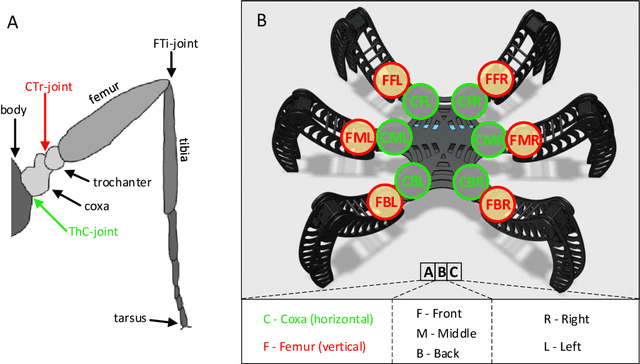
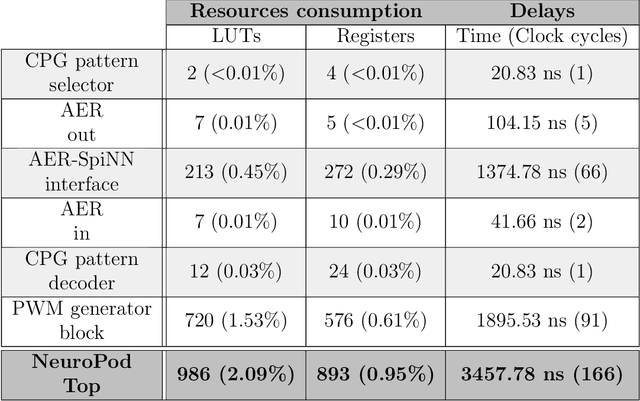
Initially, robots were developed with the aim of making our life easier, carrying out repetitive or dangerous tasks for humans. Although they were able to perform these tasks, the latest generation of robots are being designed to take a step further, by performing more complex tasks that have been carried out by smart animals or humans up to date. To this end, inspiration needs to be taken from biological examples. For instance, insects are able to optimally solve complex environment navigation problems, and many researchers have started to mimic how these insects behave. Recent interest in neuromorphic engineering has motivated us to present a real-time, neuromorphic, spike-based Central Pattern Generator of application in neurorobotics, using an arthropod-like robot. A Spiking Neural Network was designed and implemented on SpiNNaker. The network models a complex, online-change capable Central Pattern Generator which generates three gaits for a hexapod robot locomotion. Reconfigurable hardware was used to manage both the motors of the robot and the real-time communication interface with the Spiking Neural Networks. Real-time measurements confirm the simulation results, and locomotion tests show that NeuroPod can perform the gaits without any balance loss or added delay.
NullHop: A Flexible Convolutional Neural Network Accelerator Based on Sparse Representations of Feature Maps
Mar 06, 2018
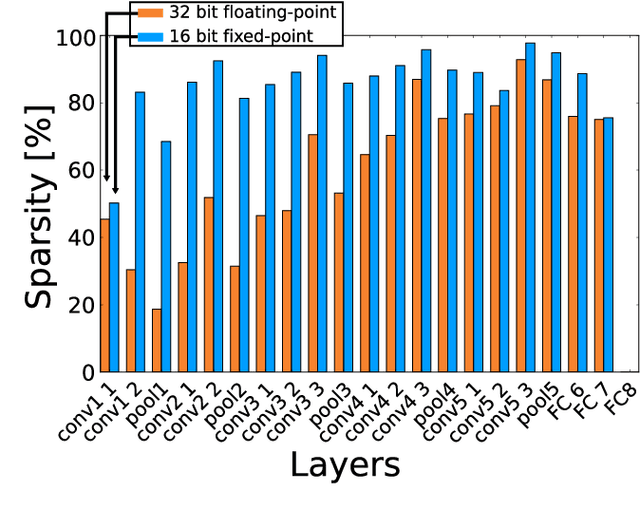
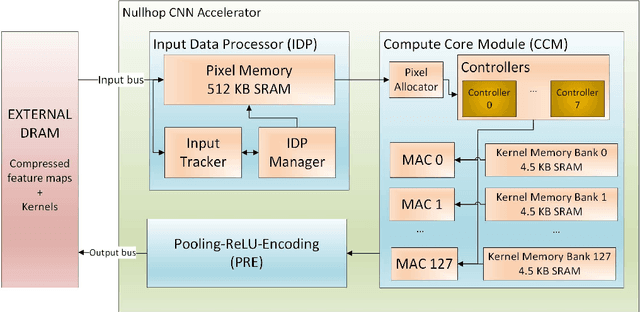
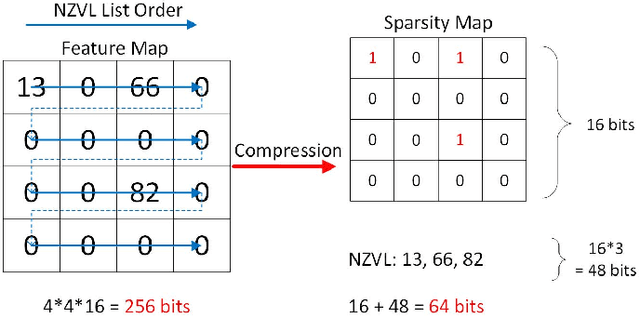
Convolutional neural networks (CNNs) have become the dominant neural network architecture for solving many state-of-the-art (SOA) visual processing tasks. Even though Graphical Processing Units (GPUs) are most often used in training and deploying CNNs, their power efficiency is less than 10 GOp/s/W for single-frame runtime inference. We propose a flexible and efficient CNN accelerator architecture called NullHop that implements SOA CNNs useful for low-power and low-latency application scenarios. NullHop exploits the sparsity of neuron activations in CNNs to accelerate the computation and reduce memory requirements. The flexible architecture allows high utilization of available computing resources across kernel sizes ranging from 1x1 to 7x7. NullHop can process up to 128 input and 128 output feature maps per layer in a single pass. We implemented the proposed architecture on a Xilinx Zynq FPGA platform and present results showing how our implementation reduces external memory transfers and compute time in five different CNNs ranging from small ones up to the widely known large VGG16 and VGG19 CNNs. Post-synthesis simulations using Mentor Modelsim in a 28nm process with a clock frequency of 500 MHz show that the VGG19 network achieves over 450 GOp/s. By exploiting sparsity, NullHop achieves an efficiency of 368%, maintains over 98% utilization of the MAC units, and achieves a power efficiency of over 3TOp/s/W in a core area of 6.3mm$^2$. As further proof of NullHop's usability, we interfaced its FPGA implementation with a neuromorphic event camera for real time interactive demonstrations.