 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Vision Sensor integration on FPGA-based CNN accelerators for high-speed visual classification
Paper and Code
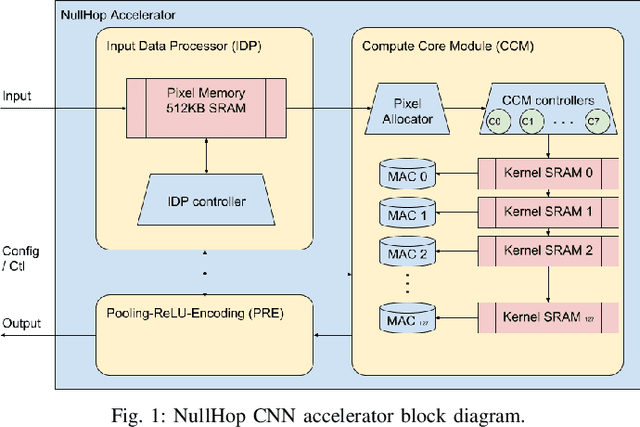
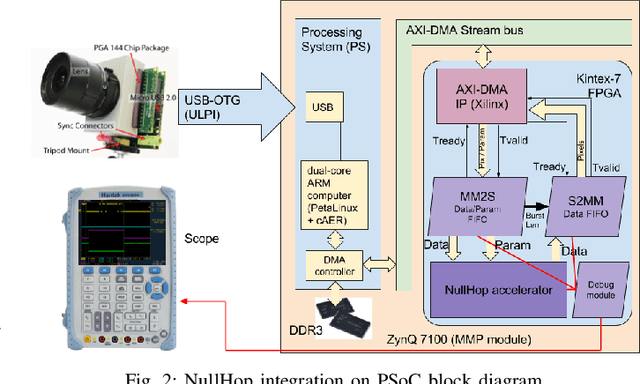
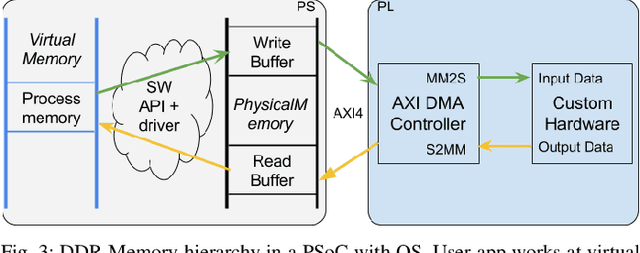
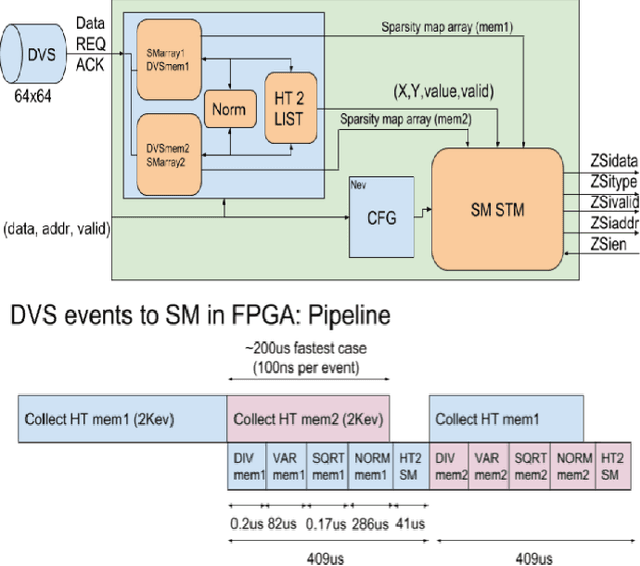
Deep-learning is a cutting edge theory that is being applied to many fields. For vision applications the Convolutional Neural Networks (CNN) are demanding significant accuracy for classification tasks. Numerous hardware accelerators have populated during the last years to improve CPU or GPU based solutions. This technology is commonly prototyped and tested over FPGAs before being considered for ASIC fabrication for mass production. The use of commercial typical cameras (30fps) limits the capabilities of these systems for high speed applications. The use of dynamic vision sensors (DVS) that emulate the behavior of a biological retina is taking an incremental importance to improve this applications due to its nature, where the information is represented by a continuous stream of spikes and the frames to be processed by the CNN are constructed collecting a fixed number of these spikes (called events). The faster an object is, the more events are produced by DVS, so the higher is the equivalent frame rate. Therefore, these DVS utilization allows to compute a frame at the maximum speed a CNN accelerator can offer. In this paper we present a VHDL/HLS description of a pipelined design for FPGA able to collect events from an Address-Event-Representation (AER) DVS retina to obtain a normalized histogram to be used by a particular CNN accelerator, called NullHop. VHDL is used to describe the circuit, and HLS for computation blocks, which are used to perform the normalization of a frame needed for the CNN. Results outperform previous implementations of frames collection and normalization using ARM processors running at 800MHz on a Zynq7100 in both latency and power consumption. A measured 67% speedup factor is presented for a Roshambo CNN real-time experiment running at 160fps peak rate.