 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Vision Sensor integration on FPGA-based CNN accelerators for high-speed visual classification
May 17, 2019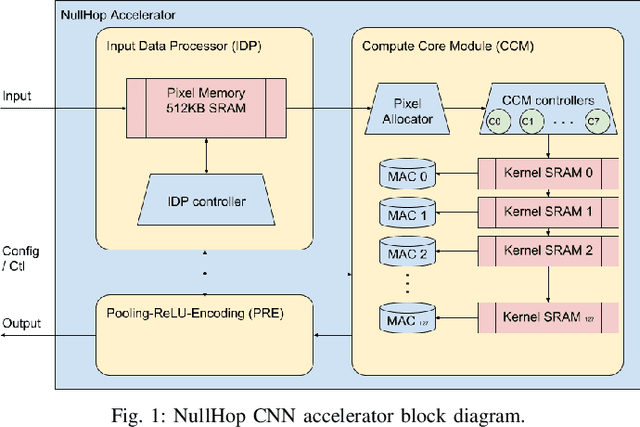
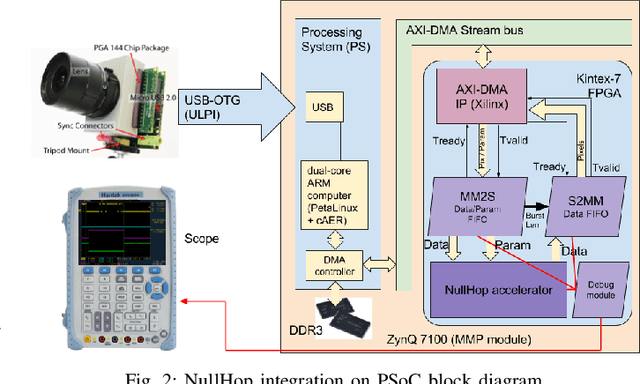
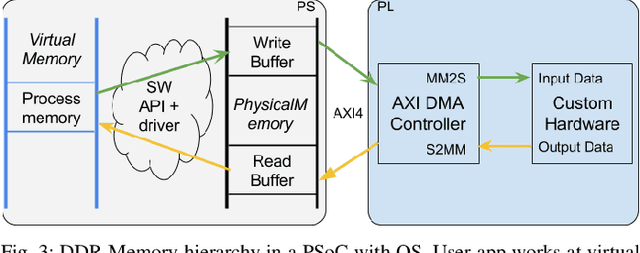
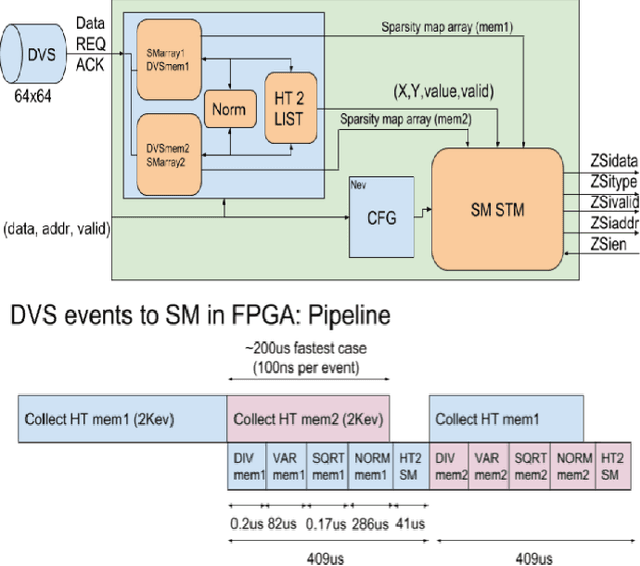
Deep-learning is a cutting edge theory that is being applied to many fields. For vision applications the Convolutional Neural Networks (CNN) are demanding significant accuracy for classification tasks. Numerous hardware accelerators have populated during the last years to improve CPU or GPU based solutions. This technology is commonly prototyped and tested over FPGAs before being considered for ASIC fabrication for mass production. The use of commercial typical cameras (30fps) limits the capabilities of these systems for high speed applications. The use of dynamic vision sensors (DVS) that emulate the behavior of a biological retina is taking an incremental importance to improve this applications due to its nature, where the information is represented by a continuous stream of spikes and the frames to be processed by the CNN are constructed collecting a fixed number of these spikes (called events). The faster an object is, the more events are produced by DVS, so the higher is the equivalent frame rate. Therefore, these DVS utilization allows to compute a frame at the maximum speed a CNN accelerator can offer. In this paper we present a VHDL/HLS description of a pipelined design for FPGA able to collect events from an Address-Event-Representation (AER) DVS retina to obtain a normalized histogram to be used by a particular CNN accelerator, called NullHop. VHDL is used to describe the circuit, and HLS for computation blocks, which are used to perform the normalization of a frame needed for the CNN. Results outperform previous implementations of frames collection and normalization using ARM processors running at 800MHz on a Zynq7100 in both latency and power consumption. A measured 67% speedup factor is presented for a Roshambo CNN real-time experiment running at 160fps peak rate.
NullHop: A Flexible Convolutional Neural Network Accelerator Based on Sparse Representations of Feature Maps
Mar 06, 2018
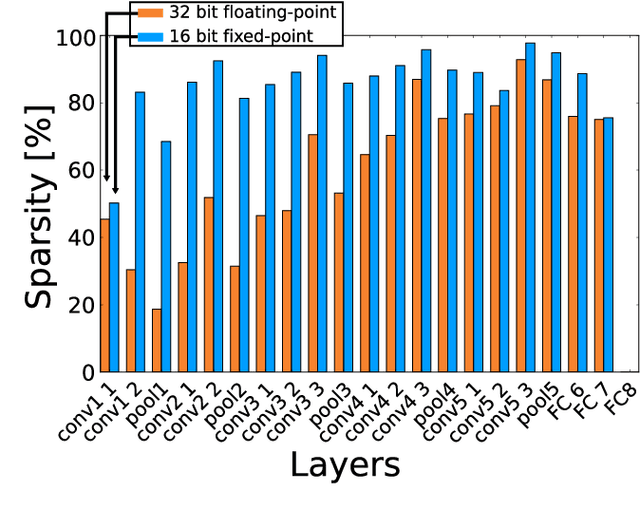
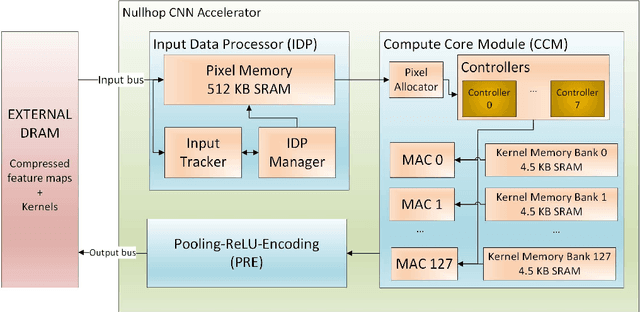
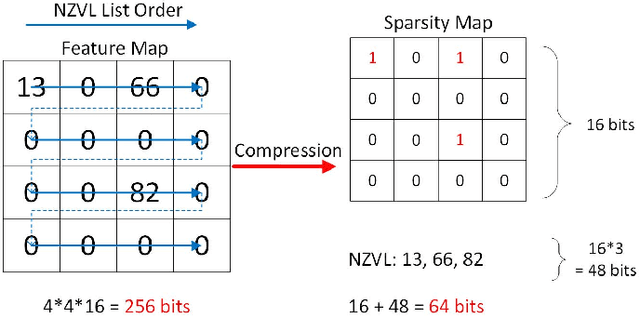
Convolutional neural networks (CNNs) have become the dominant neural network architecture for solving many state-of-the-art (SOA) visual processing tasks. Even though Graphical Processing Units (GPUs) are most often used in training and deploying CNNs, their power efficiency is less than 10 GOp/s/W for single-frame runtime inference. We propose a flexible and efficient CNN accelerator architecture called NullHop that implements SOA CNNs useful for low-power and low-latency application scenarios. NullHop exploits the sparsity of neuron activations in CNNs to accelerate the computation and reduce memory requirements. The flexible architecture allows high utilization of available computing resources across kernel sizes ranging from 1x1 to 7x7. NullHop can process up to 128 input and 128 output feature maps per layer in a single pass. We implemented the proposed architecture on a Xilinx Zynq FPGA platform and present results showing how our implementation reduces external memory transfers and compute time in five different CNNs ranging from small ones up to the widely known large VGG16 and VGG19 CNNs. Post-synthesis simulations using Mentor Modelsim in a 28nm process with a clock frequency of 500 MHz show that the VGG19 network achieves over 450 GOp/s. By exploiting sparsity, NullHop achieves an efficiency of 368%, maintains over 98% utilization of the MAC units, and achieves a power efficiency of over 3TOp/s/W in a core area of 6.3mm$^2$. As further proof of NullHop's usability, we interfaced its FPGA implementation with a neuromorphic event camera for real time interactive demonstrations.