Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIPSFUS: A neuromorphic dataset for audio-visual sensory fusion of lip reading
Mar 28, 2023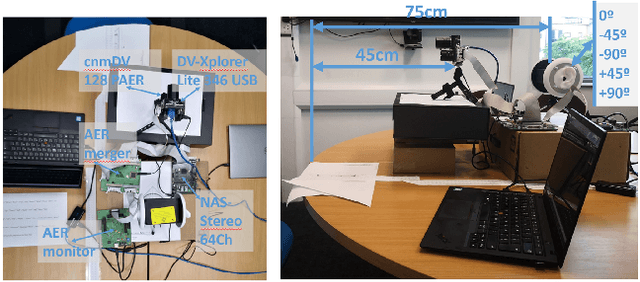
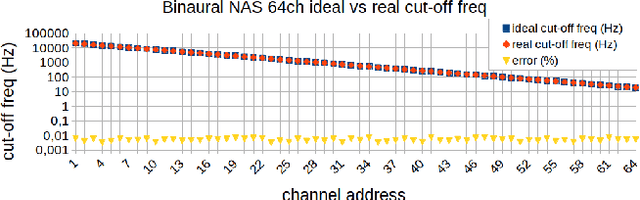
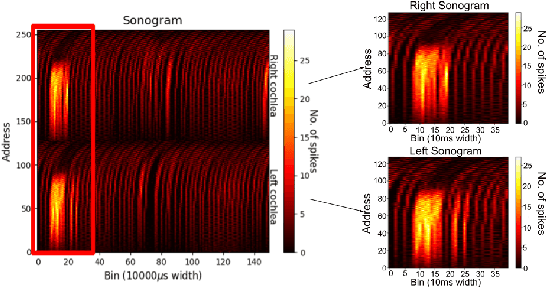
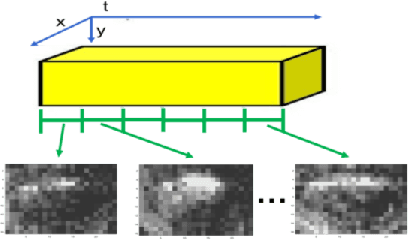
This paper presents a sensory fusion neuromorphic dataset collected with precise temporal synchronization using a set of Address-Event-Representation sensors and tools. The target application is the lip reading of several keywords for different machine learning applications, such as digits, robotic commands, and auxiliary rich phonetic short words. The dataset is enlarged with a spiking version of an audio-visual lip reading dataset collected with frame-based cameras. LIPSFUS is publicly available and it has been validated with a deep learning architecture for audio and visual classification. It is intended for sensory fusion architectures based on both artificial and spiking neural network algorithms.
* Submitted to ISCAS2023, 4 pages, plus references, github link
provided
Via