 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Curriculum Learning Method for Improved Noise Robustness in Automatic Speech Recognition
Paper and Code
Sep 16, 2016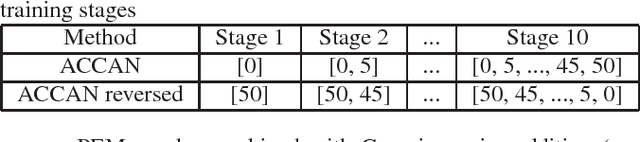
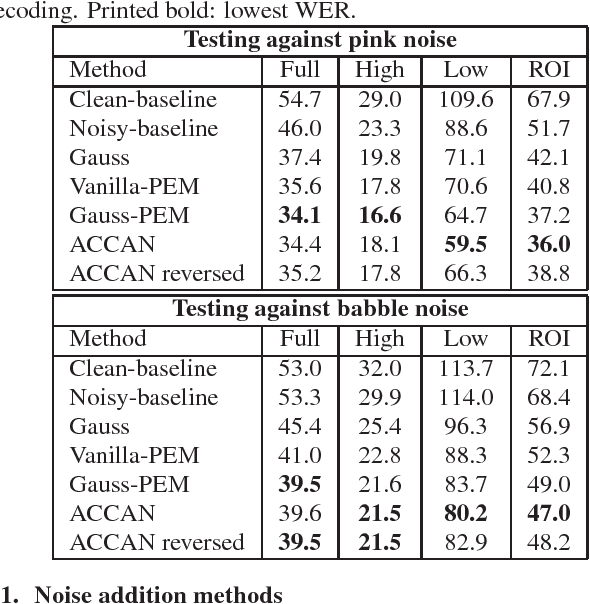
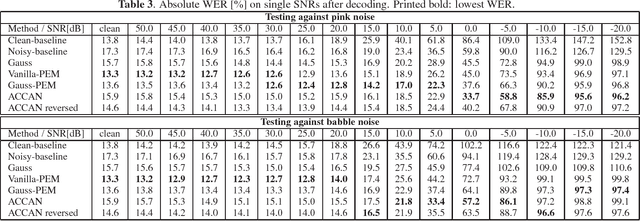
The performance of automatic speech recognition systems under noisy environments still leaves room for improvement. Speech enhancement or feature enhancement techniques for increasing noise robustness of these systems usually add components to the recognition system that need careful optimization. In this work, we propose the use of a relatively simple curriculum training strategy called accordion annealing (ACCAN). It uses a multi-stage training schedule where samples at signal-to-noise ratio (SNR) values as low as 0dB are first added and samples at increasing higher SNR values are gradually added up to an SNR value of 50dB. We also use a method called per-epoch noise mixing (PEM) that generates noisy training samples online during training and thus enables dynamically changing the SNR of our training data. Both the ACCAN and the PEM methods are evaluated on a end-to-end speech recognition pipeline on the Wall Street Journal corpus. ACCAN decreases the average word error rate (WER) on the 20dB to -10dB SNR range by up to 31.4% when compared to a conventional multi-condition training method.