 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapley Value as Principled Metric for Structured Network Pruning
Jun 02, 2020
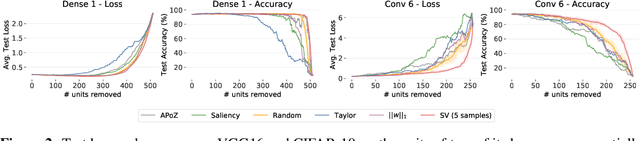

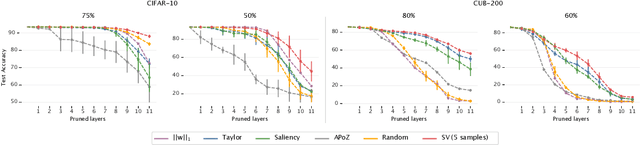
Structured pruning is a well-known technique to reduce the storage size and inference cost of neural networks. The usual pruning pipeline consists of ranking the network internal filters and activations with respect to their contributions to the network performance, removing the units with the lowest contribution, and fine-tuning the network to reduce the harm induced by pruning. Recent results showed that random pruning performs on par with other metrics, given enough fine-tuning resources. In this work, we show that this is not true on a low-data regime when fine-tuning is either not possible or not effective. In this case, reducing the harm caused by pruning becomes crucial to retain the performance of the network. First, we analyze the problem of estimating the contribution of hidden units with tools suggested by cooperative game theory and propose Shapley values as a principled ranking metric for this task. We compare with several alternatives proposed in the literature and discuss how Shapley values are theoretically preferable. Finally, we compare all ranking metrics on the challenging scenario of low-data pruning, where we demonstrate how Shapley values outperform other heuristics.
Explaining Deep Neural Networks with a Polynomial Time Algorithm for Shapley Values Approximation
Apr 12, 2019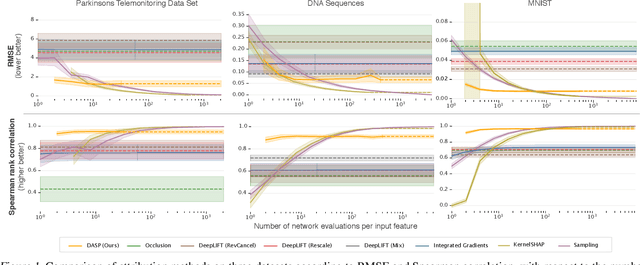

The problem of explaining the behavior of deep neural networks has gained a lot of attention over the last years. While several attribution methods have been proposed, most come without strong theoretical foundations. This raises the question of whether the resulting attributions are reliable. On the other hand, the literature on cooperative game theory suggests Shapley values as a unique way of assigning relevance scores such that certain desirable properties are satisfied. Previous works on attribution methods also showed that explanations based on Shapley values better agree with the human intuition. Unfortunately, the exact evaluation of Shapley values is prohibitively expensive, exponential in the number of input features. In this work, by leveraging recent results on uncertainty propagation, we propose a novel, polynomial-time approximation of Shapley values in deep neural networks. We show that our method produces significantly better approximations of Shapley values than existing state-of-the-art attribution methods.
Towards better understanding of gradient-based attribution methods for Deep Neural Networks
Mar 07, 2018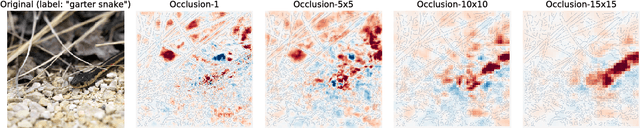
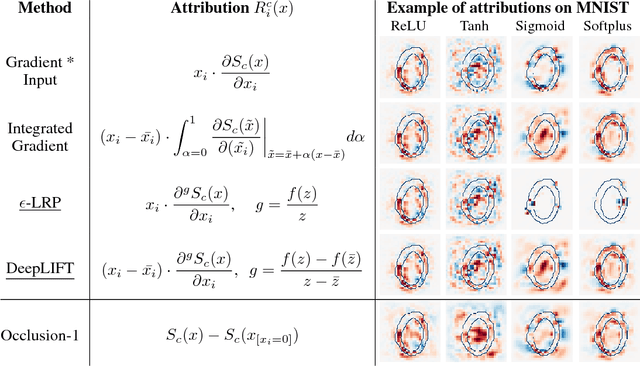


Understanding the flow of information in Deep Neural Networks (DNNs) is a challenging problem that has gain increasing attention over the last few years. While several methods have been proposed to explain network predictions, there have been only a few attempts to compare them from a theoretical perspective. What is more, no exhaustive empirical comparison has been performed in the past. In this work, we analyze four gradient-based attribution methods and formally prove conditions of equivalence and approximation between them. By reformulating two of these methods, we construct a unified framework which enables a direct comparison, as well as an easier implementation. Finally, we propose a novel evaluation metric, called Sensitivity-n and test the gradient-based attribution methods alongside with a simple perturbation-based attribution method on several datasets in the domains of image and text classification, using various network architectures.