 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamCo: Camera-Controllable 3D-Consistent Image-to-Video Generation
Paper and Code



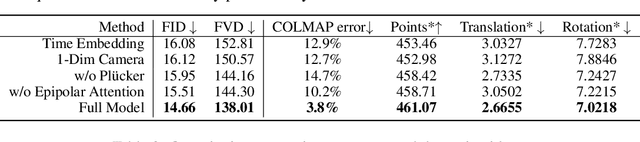
Recently video diffusion models have emerged as expressive generative tools for high-quality video content creation readily available to general users. However, these models often do not offer precise control over camera poses for video generation, limiting the expression of cinematic language and user control. To address this issue, we introduce CamCo, which allows fine-grained Camera pose Control for image-to-video generation. We equip a pre-trained image-to-video generator with accurately parameterized camera pose input using Pl\"ucker coordinates. To enhance 3D consistency in the videos produced, we integrate an epipolar attention module in each attention block that enforces epipolar constraints to the feature maps. Additionally, we fine-tune CamCo on real-world videos with camera poses estimated through structure-from-motion algorithms to better synthesize object motion. Our experiments show that CamCo significantly improves 3D consistency and camera control capabilities compared to previous models while effectively generating plausible object motion. Project page: https://ir1d.github.io/CamCo/