 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSanity-Checking Pruning Methods: Random Tickets can Win the Jackpot
Paper and Code
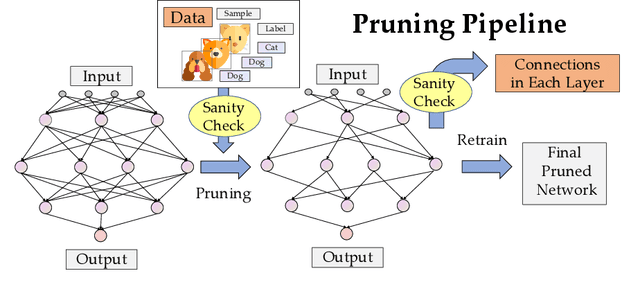
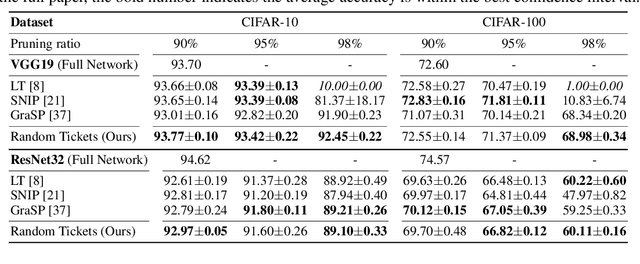
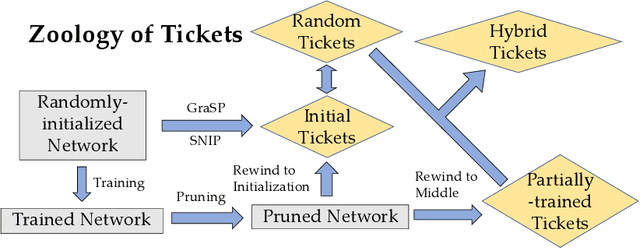
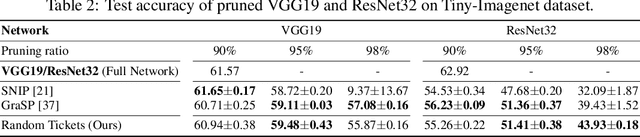
Network pruning is a method for reducing test-time computational resource requirements with minimal performance degradation. Conventional wisdom of pruning algorithms suggests that: (1) Pruning methods exploit information from training data to find good subnetworks; (2) The architecture of the pruned network is crucial for good performance. In this paper, we conduct sanity checks for the above beliefs on several recent unstructured pruning methods and surprisingly find that: (1) A set of methods which aims to find good subnetworks of the randomly-initialized network (which we call "initial tickets"), hardly exploits any information from the training data; (2) For the pruned networks obtained by these methods, randomly changing the preserved weights in each layer, while keeping the total number of preserved weights unchanged per layer, does not affect the final performance. These findings inspire us to choose a series of simple \emph{data-independent} prune ratios for each layer, and randomly prune each layer accordingly to get a subnetwork (which we call "random tickets"). Experimental results show that our zero-shot random tickets outperforms or attains similar performance compared to existing "initial tickets". In addition, we identify one existing pruning method that passes our sanity checks. We hybridize the ratios in our random ticket with this method and propose a new method called "hybrid tickets", which achieves further improvement.