 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Context for Action Detection
Jun 29, 2021
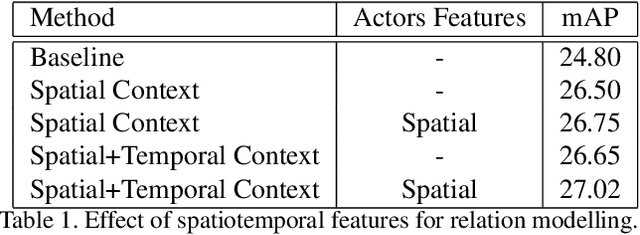


Research in action detection has grown in the recentyears, as it plays a key role in video understanding. Modelling the interactions (either spatial or temporal) between actors and their context has proven to be essential for this task. While recent works use spatial features with aggregated temporal information, this work proposes to use non-aggregated temporal information. This is done by adding an attention based method that leverages spatio-temporal interactions between elements in the scene along the clip.The main contribution of this work is the introduction of two cross attention blocks to effectively model the spatial relations and capture short range temporal interactions.Experiments on the AVA dataset show the advantages of the proposed approach that models spatio-temporal relations between relevant elements in the scene, outperforming other methods that model actor interactions with their context by +0.31 mAP.
Smooth Proxy-Anchor Loss for Noisy Metric Learning
Jun 09, 2020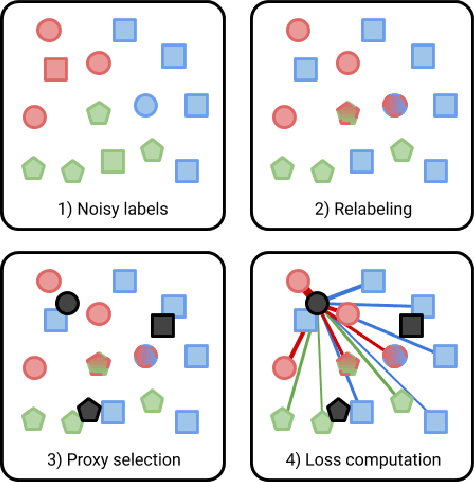
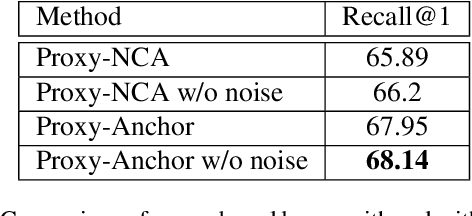
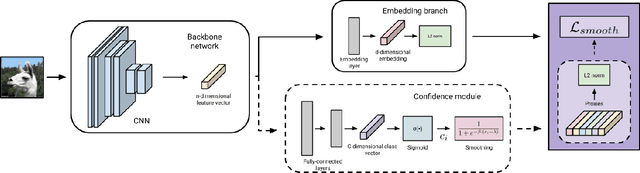
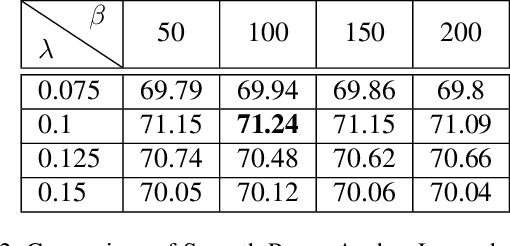
Many industrial applications use Metric Learning as a way to circumvent scalability issues when designing systems with a high number of classes. Because of this, this field of research is attracting a lot of interest from the academic and non-academic communities. Such industrial applications require large-scale datasets, which are usually generated with web data and, as a result, often contain a high number of noisy labels. While Metric Learning systems are sensitive to noisy labels, this is usually not tackled in the literature, that relies on manually annotated datasets. In this work, we propose a Metric Learning method that is able to overcome the presence of noisy labels using our novel Smooth Proxy-Anchor Loss. We also present an architecture that uses the aforementioned loss with a two-phase learning procedure. First, we train a confidence module that computes sample class confidences. Second, these confidences are used to weight the influence of each sample for the training of the embeddings. This results in a system that is able to provide robust sample embeddings. We compare the performance of the described method with current state-of-the-art Metric Learning losses (proxy-based and pair-based), when trained with a dataset containing noisy labels. The results showcase an improvement of 2.63 and 3.29 in Recall@1 with respect to MultiSimilarity and Proxy-Anchor Loss respectively, proving that our method outperforms the state-of-the-art of Metric Learning in noisy labeling conditions.
* The 4th Workshop on Visual Understanding by Learning from Web Data (CVPR 2020)
Unsupervised Multi-label Dataset Generation from Web Data
May 12, 2020


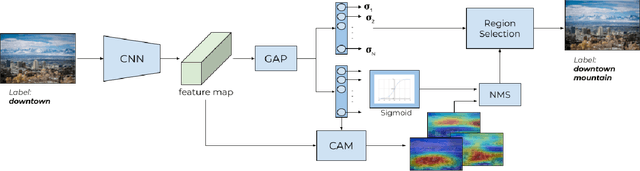
This paper presents a system towards the generation of multi-label datasets from web data in an unsupervised manner. To achieve this objective, this work comprises two main contributions, namely: a) the generation of a low-noise unsupervised single-label dataset from web-data, and b) the augmentation of labels in such dataset (from single label to multi label). The generation of a single-label dataset uses an unsupervised noise reduction phase (clustering and selection of clusters using anchors) obtaining a 85% of correctly labeled images. An unsupervised label augmentation process is then performed to assign new labels to the images in the dataset using the class activation maps and the uncertainty associated with each class. This process is applied to the dataset generated in this paper and a public dataset (Places365) achieving a 9.5% and 27% of extra labels in each dataset respectively, therefore demonstrating that the presented system can robustly enrich the initial dataset.
3D hierarchical optimization for Multi-view depth map coding
Nov 01, 2019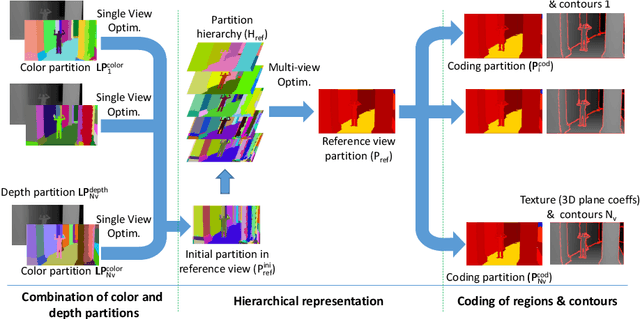


Depth data has a widespread use since the popularity of high-resolution 3D sensors. In multi-view sequences, depth information is used to supplement the color data of each view. This article proposes a joint encoding of multiple depth maps with a unique representation. Color and depth images of each view are segmented independently and combined in an optimal Rate-Distortion fashion. The resulting partitions are projected to a reference view where a coherent hierarchy for the multiple views is built. A Rate-Distortionoptimization is applied to obtain the final segmentation choosing nodes of the hierarchy. The consistent segmentation is used to robustly encode depth maps of multiple views obtaining competitive results with HEVC coding standards. Available at: http://link.springer.com/article/10.1007/s11042-017-5409-z
Multiresolution hierarchy co-clustering for semantic segmentation in sequences with small variations
Oct 16, 2015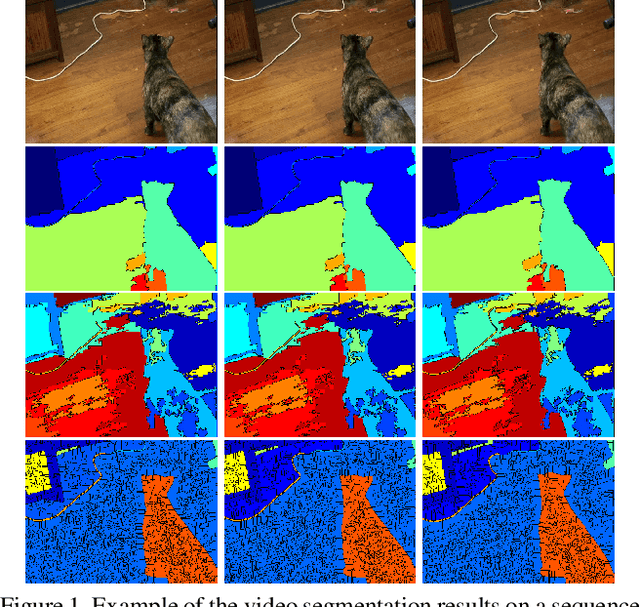
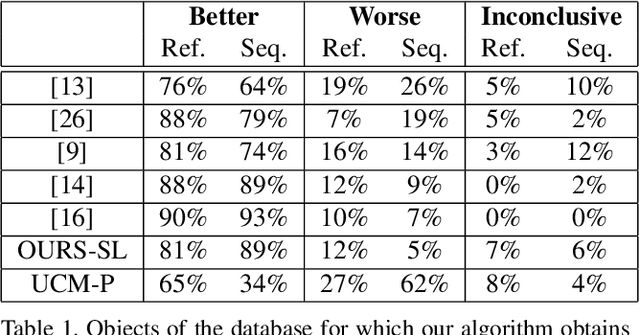
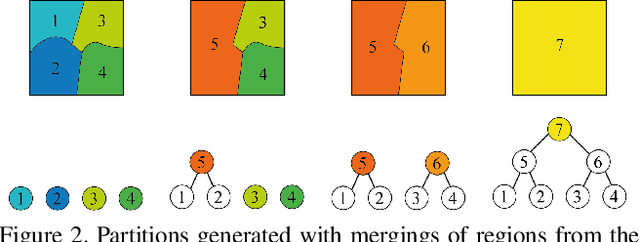

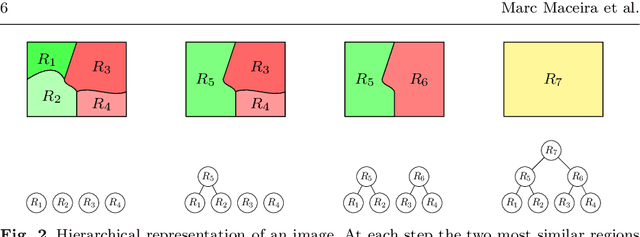
This paper presents a co-clustering technique that, given a collection of images and their hierarchies, clusters nodes from these hierarchies to obtain a coherent multiresolution representation of the image collection. We formalize the co-clustering as a Quadratic Semi-Assignment Problem and solve it with a linear programming relaxation approach that makes effective use of information from hierarchies. Initially, we address the problem of generating an optimal, coherent partition per image and, afterwards, we extend this method to a multiresolution framework. Finally, we particularize this framework to an iterative multiresolution video segmentation algorithm in sequences with small variations. We evaluate the algorithm on the Video Occlusion/Object Boundary Detection Dataset, showing that it produces state-of-the-art results in these scenarios.