 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Context for Action Detection
Jun 29, 2021
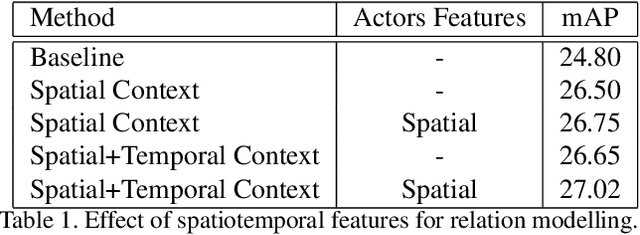


Research in action detection has grown in the recentyears, as it plays a key role in video understanding. Modelling the interactions (either spatial or temporal) between actors and their context has proven to be essential for this task. While recent works use spatial features with aggregated temporal information, this work proposes to use non-aggregated temporal information. This is done by adding an attention based method that leverages spatio-temporal interactions between elements in the scene along the clip.The main contribution of this work is the introduction of two cross attention blocks to effectively model the spatial relations and capture short range temporal interactions.Experiments on the AVA dataset show the advantages of the proposed approach that models spatio-temporal relations between relevant elements in the scene, outperforming other methods that model actor interactions with their context by +0.31 mAP.