 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewiring with Positional Encodings for Graph Neural Networks
Paper and Code
Feb 02, 2022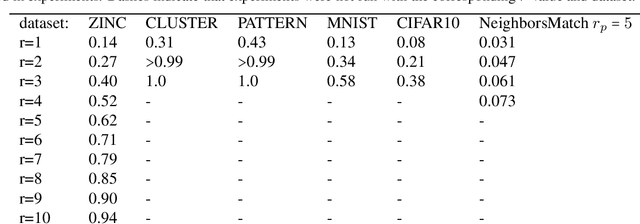
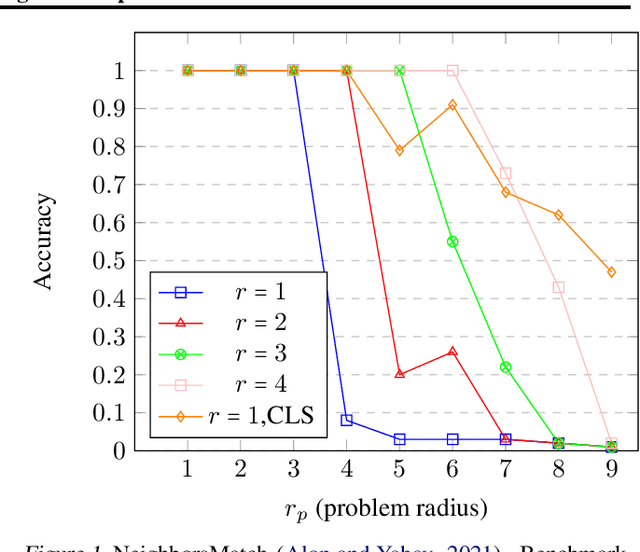
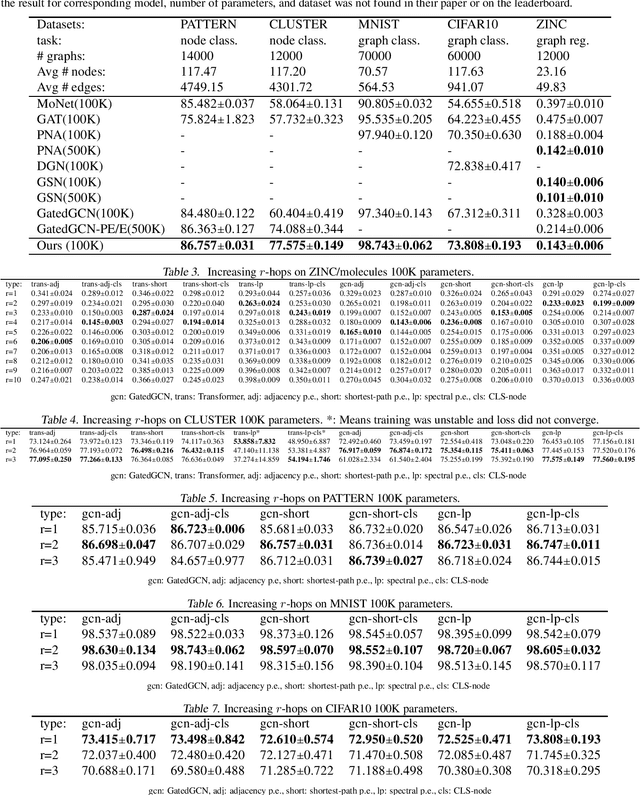
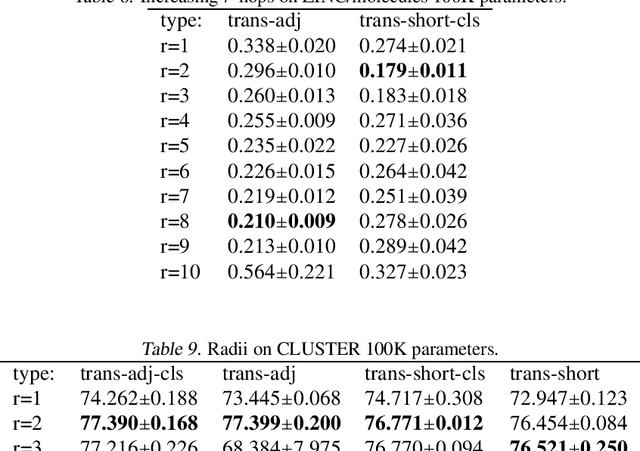
Several recent works use positional encodings to extend the receptive fields of graph neural network (GNN) layers equipped with attention mechanisms. These techniques, however, extend receptive fields to the complete graph, at substantial computational cost and risking a change in the inductive biases of conventional GNNs, or require complex architecture adjustments. As a conservative alternative, we use positional encodings to expand receptive fields to any r-ring. Our method augments the input graph with additional nodes/edges and uses positional encodings as node and/or edge features. Thus, it is compatible with many existing GNN architectures. We also provide examples of positional encodings that are non-invasive, i.e., there is a one-to-one map between the original and the modified graphs. Our experiments demonstrate that extending receptive fields via positional encodings and a virtual fully-connected node significantly improves GNN performance and alleviates over-squashing using small r. We obtain improvements across models, showing state-of-the-art performance even using older architectures than recent Transformer models adapted to graphs.