 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeRA: Label-Efficient Geometrically Regularized Alignment
Paper and Code
Oct 07, 2023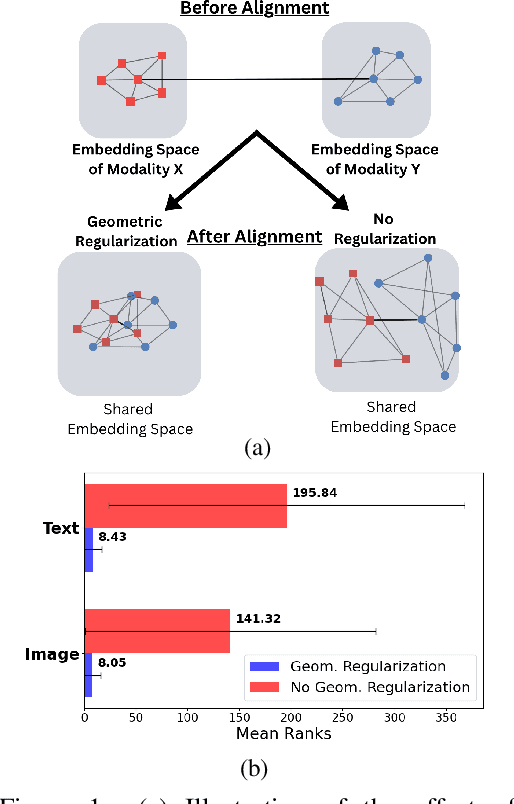
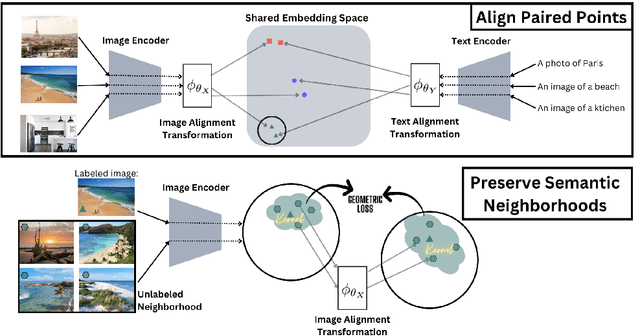
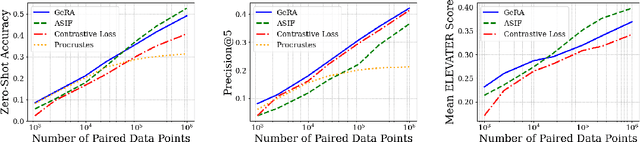
Pretrained unimodal encoders incorporate rich semantic information into embedding space structures. To be similarly informative, multi-modal encoders typically require massive amounts of paired data for alignment and training. We introduce a semi-supervised Geometrically Regularized Alignment (GeRA) method to align the embedding spaces of pretrained unimodal encoders in a label-efficient way. Our method leverages the manifold geometry of unpaired (unlabeled) data to improve alignment performance. To prevent distortions to local geometry during the alignment process, potentially disrupting semantic neighborhood structures and causing misalignment of unobserved pairs, we introduce a geometric loss term. This term is built upon a diffusion operator that captures the local manifold geometry of the unimodal pretrained encoders. GeRA is modality-agnostic and thus can be used to align pretrained encoders from any data modalities. We provide empirical evidence to the effectiveness of our method in the domains of speech-text and image-text alignment. Our experiments demonstrate significant improvement in alignment quality compared to a variaty of leading baselines, especially with a small amount of paired data, using our proposed geometric regularization.