 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMONET: A Massive, Open, Non-redundant and Enriched Text-to-image dataset
May 20, 2026Training large text-to-image models requires high-quality, curated datasets with diverse content and detailed captions. Yet the cost and complexity of collecting, filtering, deduplicating, and re-captioning such corpora at scale hinders open and reproducible research in the field. We introduce MONET, an open Apache 2.0 dataset of approx. 104.9M image--text pairs collected from 2.9B raw pairs across heterogeneous open sources through successive stages of safety filtering, domain-based filtering, exact and near-duplicate removal, and re-captioning with multiple vision-language models covering short to long-form descriptions, and further augmented with synthetically generated samples. Each image is shipped with pre-computed embeddings and annotations to accelerate downstream use. To validate the effectiveness of MONET, we train a 4B-parameter latent diffusion model exclusively on it and reach competitive GenEval and DPG scores, demonstrating that our dataset lowers the barrier to large-scale, reproducible text-to-image research.
LBM: Latent Bridge Matching for Fast Image-to-Image Translation
Mar 10, 2025In this paper, we introduce Latent Bridge Matching (LBM), a new, versatile and scalable method that relies on Bridge Matching in a latent space to achieve fast image-to-image translation. We show that the method can reach state-of-the-art results for various image-to-image tasks using only a single inference step. In addition to its efficiency, we also demonstrate the versatility of the method across different image translation tasks such as object removal, normal and depth estimation, and object relighting. We also derive a conditional framework of LBM and demonstrate its effectiveness by tackling the tasks of controllable image relighting and shadow generation. We provide an open-source implementation of the method at https://github.com/gojasper/LBM.
Controllable Shadow Generation with Single-Step Diffusion Models from Synthetic Data
Dec 16, 2024



Realistic shadow generation is a critical component for high-quality image compositing and visual effects, yet existing methods suffer from certain limitations: Physics-based approaches require a 3D scene geometry, which is often unavailable, while learning-based techniques struggle with control and visual artifacts. We introduce a novel method for fast, controllable, and background-free shadow generation for 2D object images. We create a large synthetic dataset using a 3D rendering engine to train a diffusion model for controllable shadow generation, generating shadow maps for diverse light source parameters. Through extensive ablation studies, we find that rectified flow objective achieves high-quality results with just a single sampling step enabling real-time applications. Furthermore, our experiments demonstrate that the model generalizes well to real-world images. To facilitate further research in evaluating quality and controllability in shadow generation, we release a new public benchmark containing a diverse set of object images and shadow maps in various settings. The project page is available at https://gojasper.github.io/controllable-shadow-generation-project/
Flash Diffusion: Accelerating Any Conditional Diffusion Model for Few Steps Image Generation
Jun 04, 2024In this paper, we propose an efficient, fast, and versatile distillation method to accelerate the generation of pre-trained diffusion models: Flash Diffusion. The method reaches state-of-the-art performances in terms of FID and CLIP-Score for few steps image generation on the COCO2014 and COCO2017 datasets, while requiring only several GPU hours of training and fewer trainable parameters than existing methods. In addition to its efficiency, the versatility of the method is also exposed across several tasks such as text-to-image, inpainting, face-swapping, super-resolution and using different backbones such as UNet-based denoisers (SD1.5, SDXL) or DiT (Pixart-$\alpha$), as well as adapters. In all cases, the method allowed to reduce drastically the number of sampling steps while maintaining very high-quality image generation. The official implementation is available at https://github.com/gojasper/flash-diffusion.
DAugNet: Unsupervised, Multi-source, Multi-target, and Life-long Domain Adaptation for Semantic Segmentation of Satellite Images
Jun 07, 2020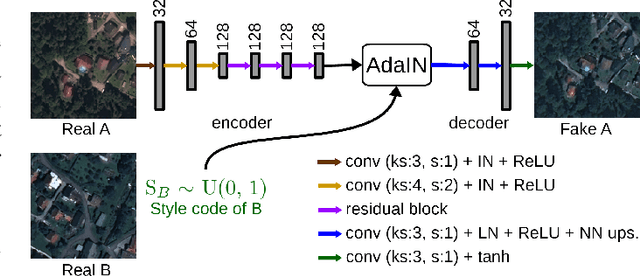
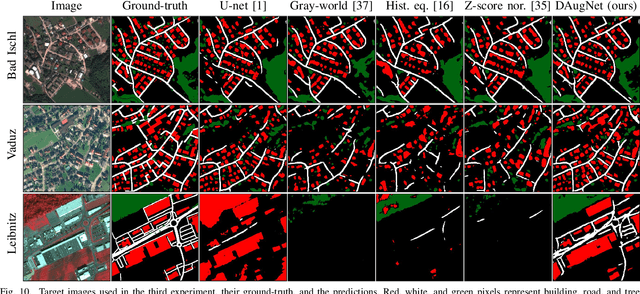
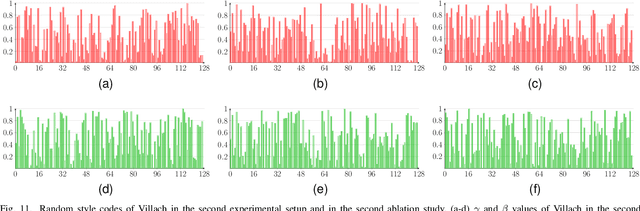

The domain adaptation of satellite images has recently gained an increasing attention to overcome the limited generalization abilities of machine learning models when segmenting large-scale satellite images. Most of the existing approaches seek for adapting the model from one domain to another. However, such single-source and single-target setting prevents the methods from being scalable solutions, since nowadays multiple source and target domains having different data distributions are usually available. Besides, the continuous proliferation of satellite images necessitates the classifiers to adapt to continuously increasing data. We propose a novel approach, coined DAugNet, for unsupervised, multi-source, multi-target, and life-long domain adaptation of satellite images. It consists of a classifier and a data augmentor. The data augmentor, which is a shallow network, is able to perform style transfer between multiple satellite images in an unsupervised manner, even when new data are added over the time. In each training iteration, it provides the classifier with diversified data, which makes the classifier robust to large data distribution difference between the domains. Our extensive experiments prove that DAugNet significantly better generalizes to new geographic locations than the existing approaches.
StandardGAN: Multi-source Domain Adaptation for Semantic Segmentation of Very High Resolution Satellite Images by Data Standardization
Apr 14, 2020
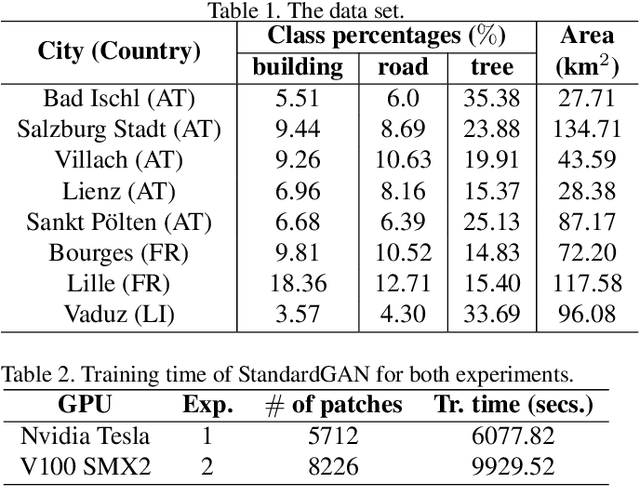
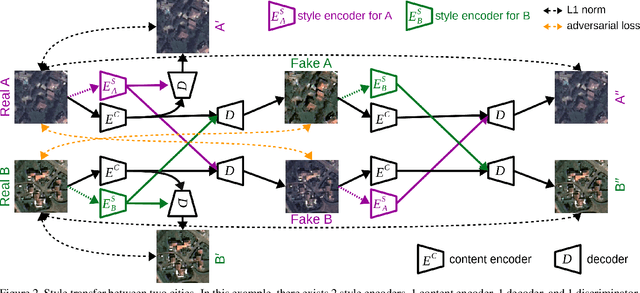
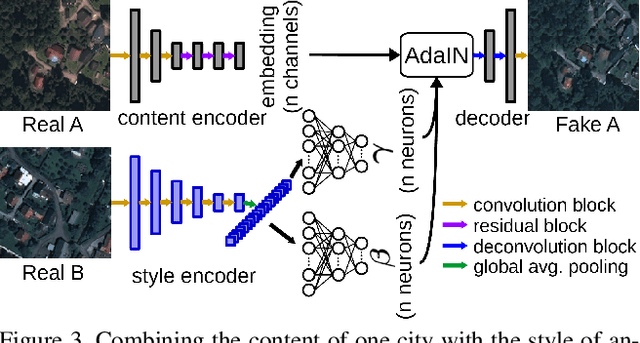
Domain adaptation for semantic segmentation has recently been actively studied to increase the generalization capabilities of deep learning models. The vast majority of the domain adaptation methods tackle single-source case, where the model trained on a single source domain is adapted to a target domain. However, these methods have limited practical real world applications, since usually one has multiple source domains with different data distributions. In this work, we deal with the multi-source domain adaptation problem. Our method, namely StandardGAN, standardizes each source and target domains so that all the data have similar data distributions. We then use the standardized source domains to train a classifier and segment the standardized target domain. We conduct extensive experiments on two remote sensing data sets, in which the first one consists of multiple cities from a single country, and the other one contains multiple cities from different countries. Our experimental results show that the standardized data generated by StandardGAN allow the classifiers to generate significantly better segmentation.
SemI2I: Semantically Consistent Image-to-Image Translation for Domain Adaptation of Remote Sensing Data
Feb 21, 2020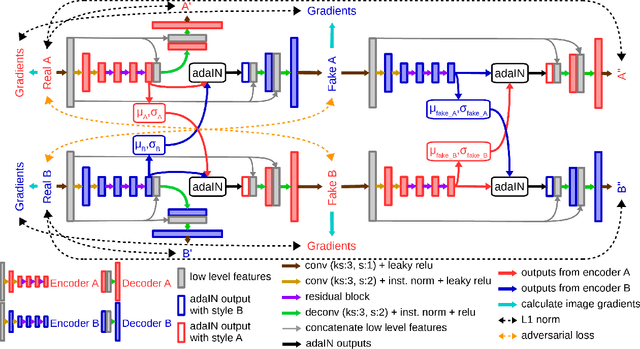
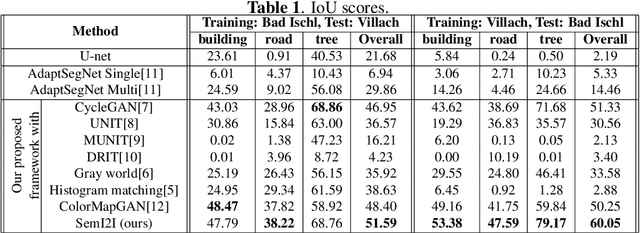

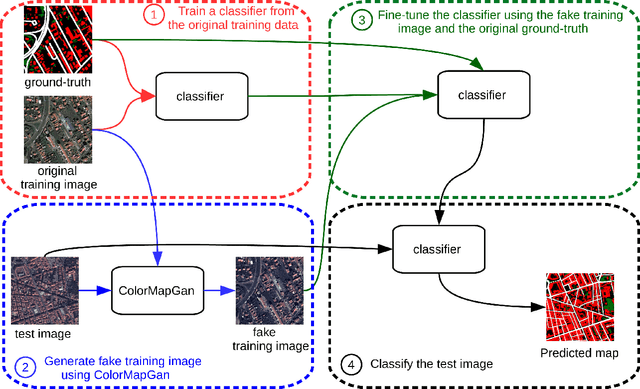
Although convolutional neural networks have been proven to be an effective tool to generate high quality maps from remote sensing images, their performance significantly deteriorates when there exists a large domain shift between training and test data. To address this issue, we propose a new data augmentation approach that transfers the style of test data to training data using generative adversarial networks. Our semantic segmentation framework consists in first training a U-net from the real training data and then fine-tuning it on the test stylized fake training data generated by the proposed approach. Our experimental results prove that our framework outperforms the existing domain adaptation methods.
ColorMapGAN: Unsupervised Domain Adaptation for Semantic Segmentation Using Color Mapping Generative Adversarial Networks
Jul 30, 2019
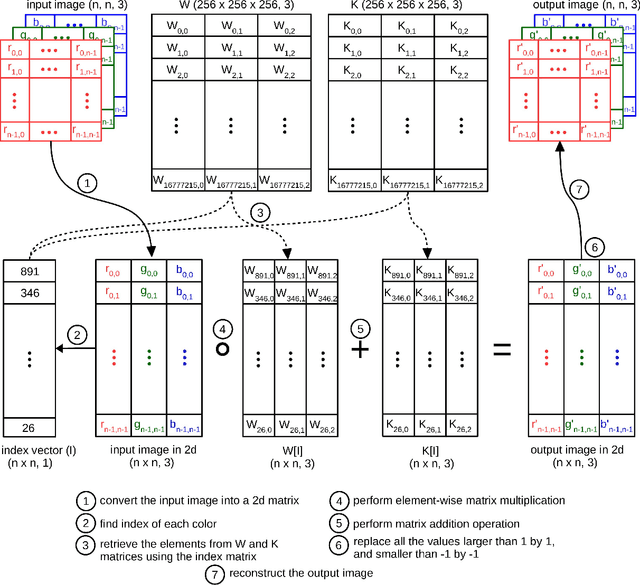
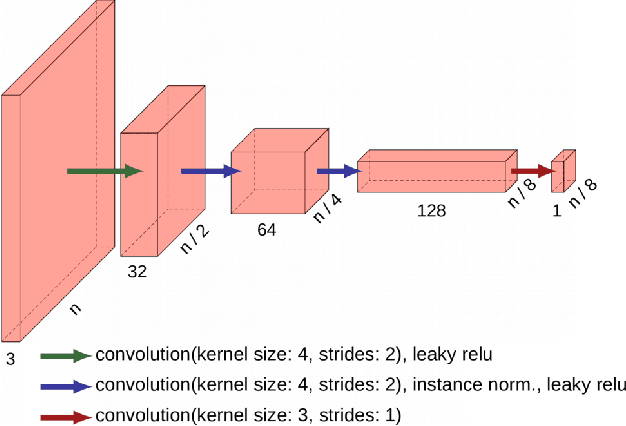
Due to the various reasons such as atmospheric effects and differences in acquisition, it is often the case that there exists a large difference between spectral bands of satellite images collected from different geographic locations. The large shift between spectral distributions of training and test data causes the current state of the art supervised learning approaches to output poor maps. We present a novel end to end semantic segmentation framework that is robust to such shift. The key component of the proposed framework is Color Mapping Generative Adversarial Networks (ColorMapGAN), which can generate fake training images that are semantically exactly the same as training images, but whose spectral distribution is similar to the distribution of the test images. We then use the fake images and the ground-truth for the training images to fine-tune the already trained classifier. Contrary to the existing Generative Adversarial Networks (GAN), the generator in ColorMapGAN does not have any convolutional or pooling layers. It learns to transform the colors of the training data to the colors of the test data by performing only one element-wise matrix multiplication and one matrix addition operations. Thanks to the architecturally simple but powerful design of ColorMapGAN, the proposed framework outperforms the existing approaches with a large margin in terms of both accuracy and computational complexity.
Incremental Learning for Semantic Segmentation of Large-Scale Remote Sensing Data
Oct 29, 2018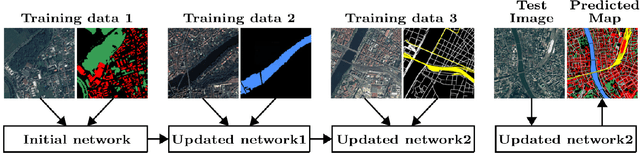
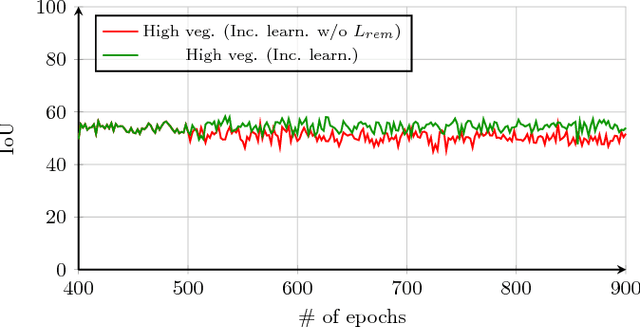
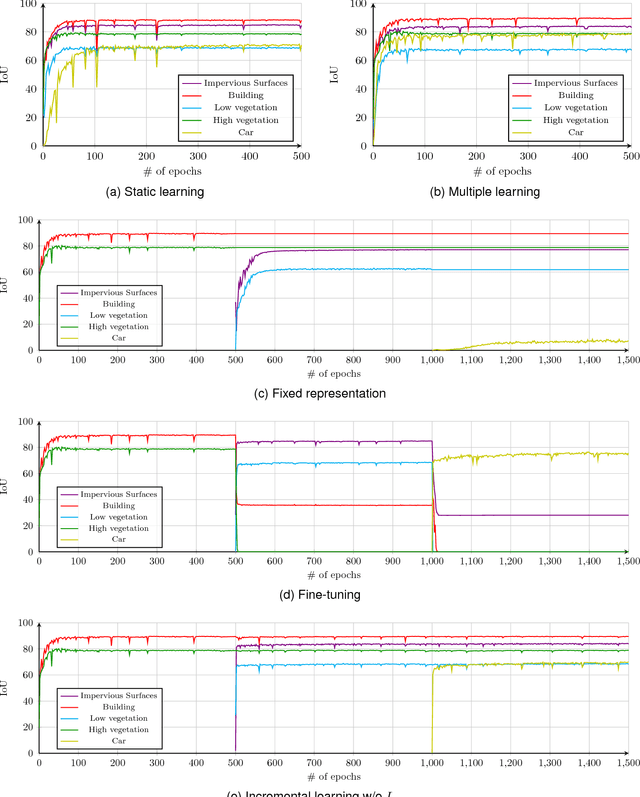
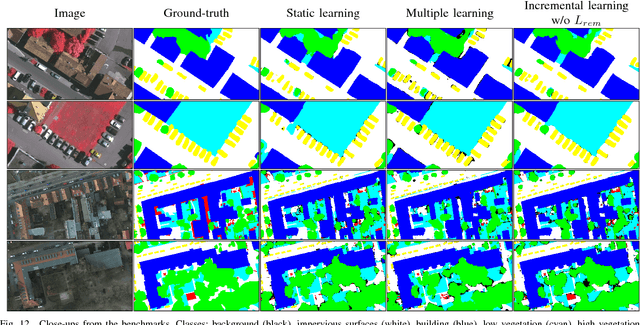
In spite of remarkable success of the convolutional neural networks on semantic segmentation, they suffer from catastrophic forgetting: a significant performance drop for the already learned classes when new classes are added on the data, having no annotations for the old classes. We propose an incremental learning methodology, enabling to learn segmenting new classes without hindering dense labeling abilities for the previous classes, although the entire previous data are not accessible. The key points of the proposed approach are adapting the network to learn new as well as old classes on the new training data, and allowing it to remember the previously learned information for the old classes. For adaptation, we keep a frozen copy of the previously trained network, which is used as a memory for the updated network in absence of annotations for the former classes. The updated network minimizes a loss function, which balances the discrepancy between outputs for the previous classes from the memory and updated networks, and the mis-classification rate between outputs for the new classes from the updated network and the new ground-truth. For remembering, we either regularly feed samples from the stored, little fraction of the previous data or use the memory network, depending on whether the new data are collected from completely different geographic areas or from the same city. Our experimental results prove that it is possible to add new classes to the network, while maintaining its performance for the previous classes, despite the whole previous training data are not available.
Evaluation of Joint Multi-Instance Multi-Label Learning For Breast Cancer Diagnosis
Oct 10, 2015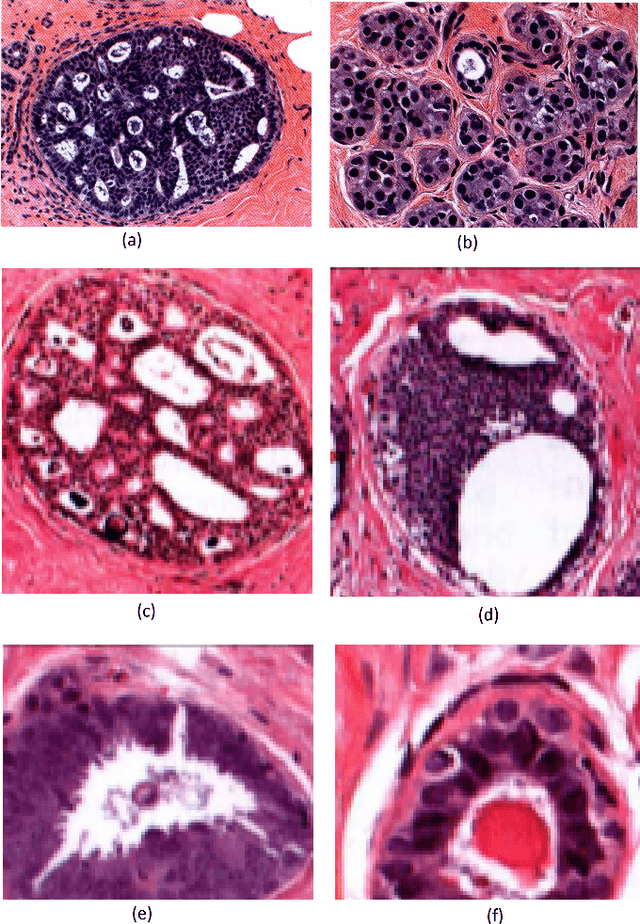
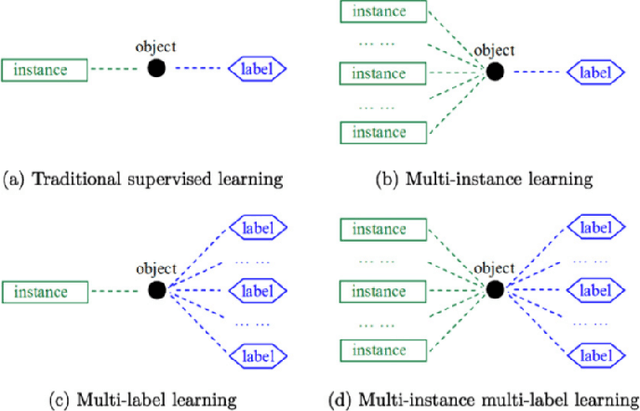

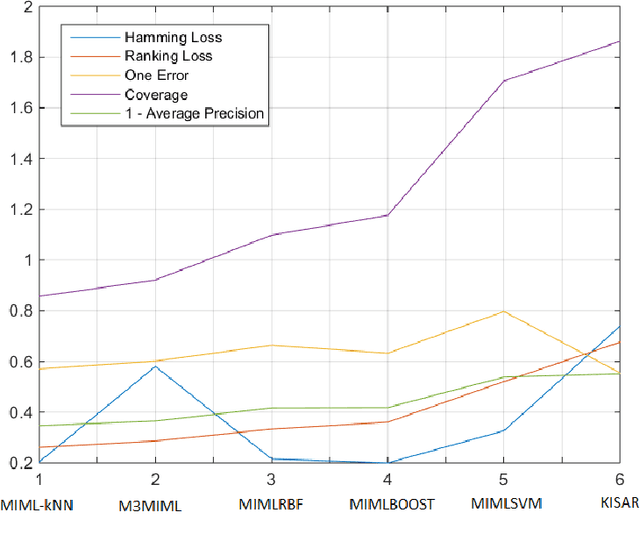
Multi-instance multi-label (MIML) learning is a challenging problem in many aspects. Such learning approaches might be useful for many medical diagnosis applications including breast cancer detection and classification. In this study subset of digiPATH dataset (whole slide digital breast cancer histopathology images) are used for training and evaluation of six state-of-the-art MIML methods. At the end, performance comparison of these approaches are given by means of effective evaluation metrics. It is shown that MIML-kNN achieve the best performance that is %65.3 average precision, where most of other methods attain acceptable results as well.