 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Instance Attention for Multisource Fine-Grained Object Recognition with an Application to Tree Species Classification
May 25, 2021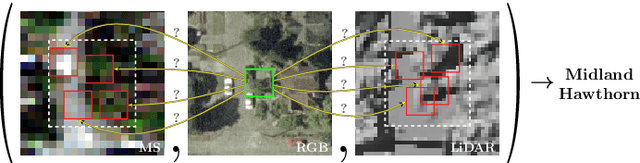

Multisource image analysis that leverages complementary spectral, spatial, and structural information benefits fine-grained object recognition that aims to classify an object into one of many similar subcategories. However, for multisource tasks that involve relatively small objects, even the smallest registration errors can introduce high uncertainty in the classification process. We approach this problem from a weakly supervised learning perspective in which the input images correspond to larger neighborhoods around the expected object locations where an object with a given class label is present in the neighborhood without any knowledge of its exact location. The proposed method uses a single-source deep instance attention model with parallel branches for joint localization and classification of objects, and extends this model into a multisource setting where a reference source that is assumed to have no location uncertainty is used to aid the fusion of multiple sources in four different levels: probability level, logit level, feature level, and pixel level. We show that all levels of fusion provide higher accuracies compared to the state-of-the-art, with the best performing method of feature-level fusion resulting in 53% accuracy for the recognition of 40 different types of trees, corresponding to an improvement of 5.7% over the best performing baseline when RGB, multispectral, and LiDAR data are used. We also provide an in-depth comparison by evaluating each model at various parameter complexity settings, where the increased model capacity results in a further improvement of 6.3% over the default capacity setting.
Multisource Region Attention Network for Fine-Grained Object Recognition in Remote Sensing Imagery
Jan 18, 2019
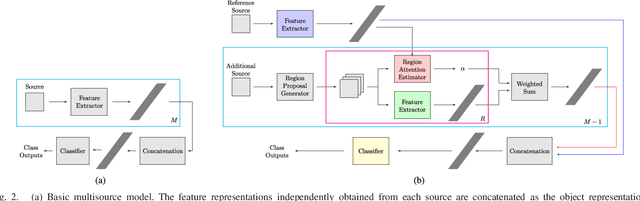
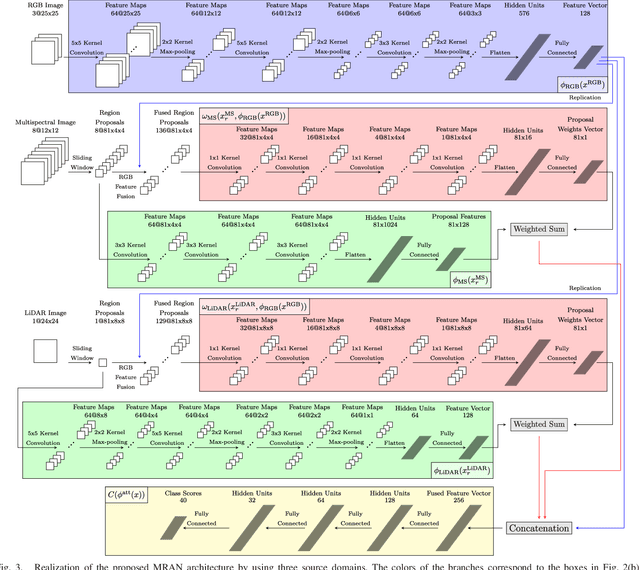

Fine-grained object recognition concerns the identification of the type of an object among a large number of closely related sub-categories. Multisource data analysis, that aims to leverage the complementary spectral, spatial, and structural information embedded in different sources, is a promising direction towards solving the fine-grained recognition problem that involves low between-class variance, small training set sizes for rare classes, and class imbalance. However, the common assumption of co-registered sources may not hold at the pixel level for small objects of interest. We present a novel methodology that aims to simultaneously learn the alignment of multisource data and the classification model in a unified framework. The proposed method involves a multisource region attention network that computes per-source feature representations, assigns attention scores to candidate regions sampled around the expected object locations by using these representations, and classifies the objects by using an attention-driven multisource representation that combines the feature representations and the attention scores from all sources. All components of the model are realized using deep neural networks and are learned in an end-to-end fashion. Experiments using RGB, multispectral, and LiDAR elevation data for classification of street trees showed that our approach achieved 64.2% and 47.3% accuracies for the 18-class and 40-class settings, respectively, which correspond to 13% and 14.3% improvement relative to the commonly used feature concatenation approach from multiple sources.
Fine-Grained Object Recognition and Zero-Shot Learning in Remote Sensing Imagery
Dec 09, 2017



Fine-grained object recognition that aims to identify the type of an object among a large number of subcategories is an emerging application with the increasing resolution that exposes new details in image data. Traditional fully supervised algorithms fail to handle this problem where there is low between-class variance and high within-class variance for the classes of interest with small sample sizes. We study an even more extreme scenario named zero-shot learning (ZSL) in which no training example exists for some of the classes. ZSL aims to build a recognition model for new unseen categories by relating them to seen classes that were previously learned. We establish this relation by learning a compatibility function between image features extracted via a convolutional neural network and auxiliary information that describes the semantics of the classes of interest by using training samples from the seen classes. Then, we show how knowledge transfer can be performed for the unseen classes by maximizing this function during inference. We introduce a new data set that contains 40 different types of street trees in 1-ft spatial resolution aerial data, and evaluate the performance of this model with manually annotated attributes, a natural language model, and a scientific taxonomy as auxiliary information. The experiments show that the proposed model achieves 14.3% recognition accuracy for the classes with no training examples, which is significantly better than a random guess accuracy of 6.3% for 16 test classes, and three other ZSL algorithms.
Evaluation of Joint Multi-Instance Multi-Label Learning For Breast Cancer Diagnosis
Oct 10, 2015
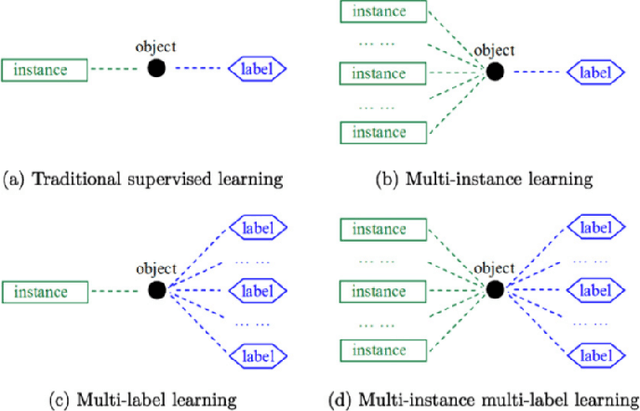

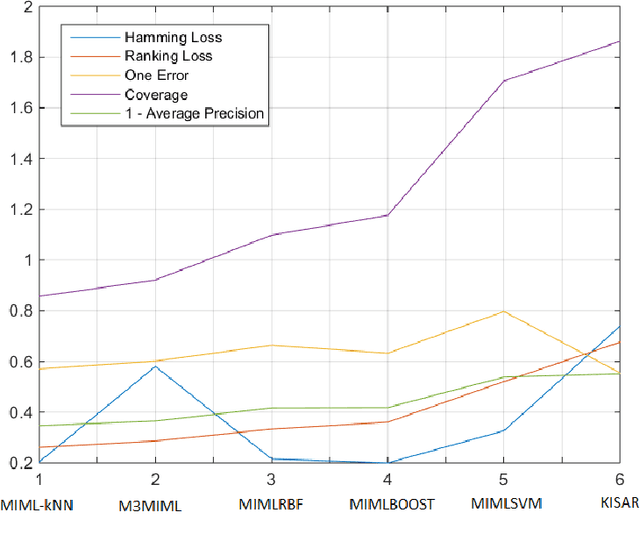
Multi-instance multi-label (MIML) learning is a challenging problem in many aspects. Such learning approaches might be useful for many medical diagnosis applications including breast cancer detection and classification. In this study subset of digiPATH dataset (whole slide digital breast cancer histopathology images) are used for training and evaluation of six state-of-the-art MIML methods. At the end, performance comparison of these approaches are given by means of effective evaluation metrics. It is shown that MIML-kNN achieve the best performance that is %65.3 average precision, where most of other methods attain acceptable results as well.