 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathHay: An Automated Benchmark for Long-Context Mathematical Reasoning in LLMs
Oct 07, 2024



Recent large language models (LLMs) have demonstrated versatile capabilities in long-context scenarios. Although some recent benchmarks have been developed to evaluate the long-context capabilities of LLMs, there is a lack of benchmarks evaluating the mathematical reasoning abilities of LLMs over long contexts, which is crucial for LLMs' application in real-world scenarios. In this paper, we introduce MathHay, an automated benchmark designed to assess the long-context mathematical reasoning capabilities of LLMs. Unlike previous benchmarks like Needle in a Haystack, which focus primarily on information retrieval within long texts, MathHay demands models with both information-seeking and complex mathematical reasoning abilities. We conduct extensive experiments on MathHay to assess the long-context mathematical reasoning abilities of eight top-performing LLMs. Even the best-performing model, Gemini-1.5-Pro-002, still struggles with mathematical reasoning over long contexts, achieving only 51.26% accuracy at 128K tokens. This highlights the significant room for improvement on the MathHay benchmark.
All in a Single Image: Large Multimodal Models are In-Image Learners
Feb 28, 2024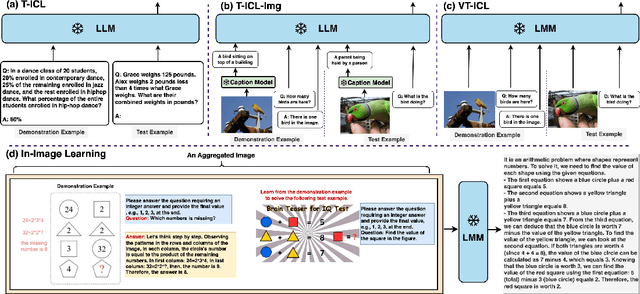
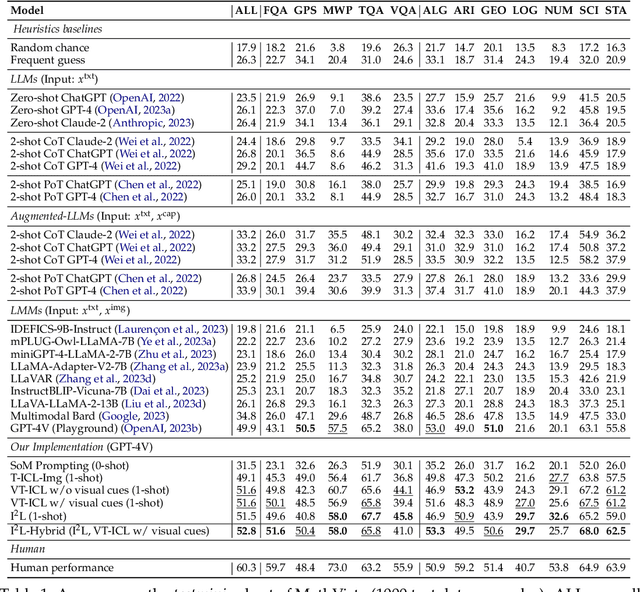
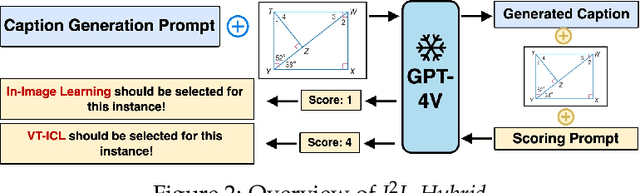

This paper introduces a new in-context learning (ICL) mechanism called In-Image Learning (I$^2$L) that combines demonstration examples, visual cues, and instructions into a single image to enhance the capabilities of GPT-4V. Unlike previous approaches that rely on converting images to text or incorporating visual input into language models, I$^2$L consolidates all information into one image and primarily leverages image processing, understanding, and reasoning abilities. This has several advantages: it avoids inaccurate textual descriptions of complex images, provides flexibility in positioning demonstration examples, reduces the input burden, and avoids exceeding input limits by eliminating the need for multiple images and lengthy text. To further combine the strengths of different ICL methods, we introduce an automatic strategy to select the appropriate ICL method for a data example in a given task. We conducted experiments on MathVista and Hallusionbench to test the effectiveness of I$^2$L in complex multimodal reasoning tasks and mitigating language hallucination and visual illusion. Additionally, we explored the impact of image resolution, the number of demonstration examples, and their positions on the effectiveness of I$^2$L. Our code is publicly available at https://github.com/AGI-Edgerunners/IIL.