 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll in a Single Image: Large Multimodal Models are In-Image Learners
Feb 28, 2024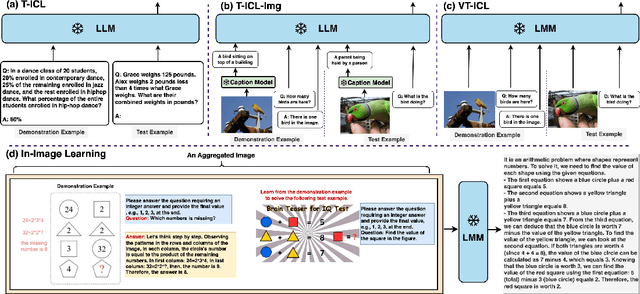
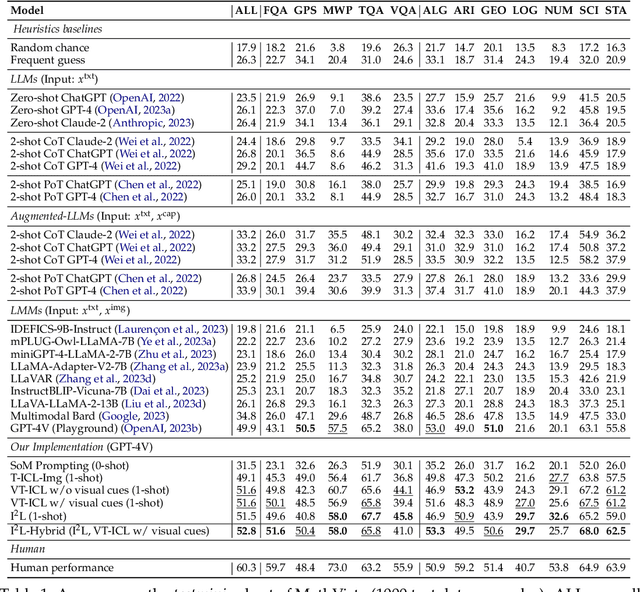
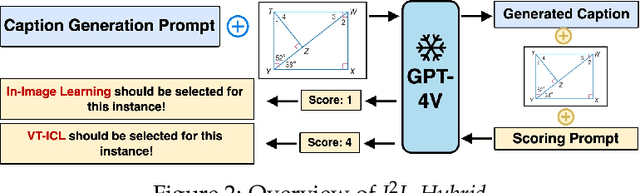

This paper introduces a new in-context learning (ICL) mechanism called In-Image Learning (I$^2$L) that combines demonstration examples, visual cues, and instructions into a single image to enhance the capabilities of GPT-4V. Unlike previous approaches that rely on converting images to text or incorporating visual input into language models, I$^2$L consolidates all information into one image and primarily leverages image processing, understanding, and reasoning abilities. This has several advantages: it avoids inaccurate textual descriptions of complex images, provides flexibility in positioning demonstration examples, reduces the input burden, and avoids exceeding input limits by eliminating the need for multiple images and lengthy text. To further combine the strengths of different ICL methods, we introduce an automatic strategy to select the appropriate ICL method for a data example in a given task. We conducted experiments on MathVista and Hallusionbench to test the effectiveness of I$^2$L in complex multimodal reasoning tasks and mitigating language hallucination and visual illusion. Additionally, we explored the impact of image resolution, the number of demonstration examples, and their positions on the effectiveness of I$^2$L. Our code is publicly available at https://github.com/AGI-Edgerunners/IIL.
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
May 06, 2023Large language models (LLMs) have recently been shown to deliver impressive performance in various NLP tasks. To tackle multi-step reasoning tasks, few-shot chain-of-thought (CoT) prompting includes a few manually crafted step-by-step reasoning demonstrations which enable LLMs to explicitly generate reasoning steps and improve their reasoning task accuracy. To eliminate the manual effort, Zero-shot-CoT concatenates the target problem statement with "Let's think step by step" as an input prompt to LLMs. Despite the success of Zero-shot-CoT, it still suffers from three pitfalls: calculation errors, missing-step errors, and semantic misunderstanding errors. To address the missing-step errors, we propose Plan-and-Solve (PS) Prompting. It consists of two components: first, devising a plan to divide the entire task into smaller subtasks, and then carrying out the subtasks according to the plan. To address the calculation errors and improve the quality of generated reasoning steps, we extend PS prompting with more detailed instructions and derive PS+ prompting. We evaluate our proposed prompting strategy on ten datasets across three reasoning problems. The experimental results over GPT-3 show that our proposed zero-shot prompting consistently outperforms Zero-shot-CoT across all datasets by a large margin, is comparable to or exceeds Zero-shot-Program-of-Thought Prompting, and has comparable performance with 8-shot CoT prompting on the math reasoning problem. The code can be found at https://github.com/AGI-Edgerunners/Plan-and-Solve-Prompting.
LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models
Apr 04, 2023The success of large language models (LLMs), like GPT-3 and ChatGPT, has led to the development of numerous cost-effective and accessible alternatives that are created by fine-tuning open-access LLMs with task-specific data (e.g., ChatDoctor) or instruction data (e.g., Alpaca). Among the various fine-tuning methods, adapter-based parameter-efficient fine-tuning (PEFT) is undoubtedly one of the most attractive topics, as it only requires fine-tuning a few external parameters instead of the entire LLMs while achieving comparable or even better performance. To enable further research on PEFT methods of LLMs, this paper presents LLM-Adapters, an easy-to-use framework that integrates various adapters into LLMs and can execute these adapter-based PEFT methods of LLMs for different tasks. The framework includes state-of-the-art open-access LLMs such as LLaMA, BLOOM, OPT, and GPT-J, as well as widely used adapters such as Series adapter, Parallel adapter, and LoRA. The framework is designed to be research-friendly, efficient, modular, and extendable, allowing the integration of new adapters and the evaluation of them with new and larger-scale LLMs. Furthermore, to evaluate the effectiveness of adapters in LLMs-Adapters, we conduct experiments on six math reasoning datasets. The results demonstrate that using adapter-based PEFT in smaller-scale LLMs (7B) with few extra trainable parameters yields comparable, and in some cases superior, performance to that of powerful LLMs (175B) in zero-shot inference on simple math reasoning datasets. Overall, we provide a promising framework for fine-tuning large LLMs on downstream tasks. We believe the proposed LLMs-Adapters will advance adapter-based PEFT research, facilitate the deployment of research pipelines, and enable practical applications to real-world systems.
Unsupervised Domain Adaptation with Implicit Pseudo Supervision for Semantic Segmentation
Apr 14, 2022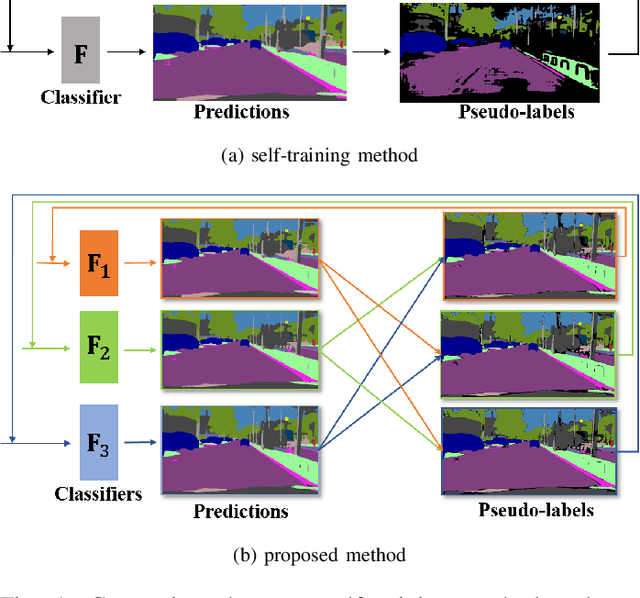
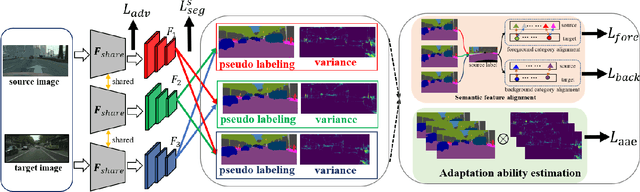
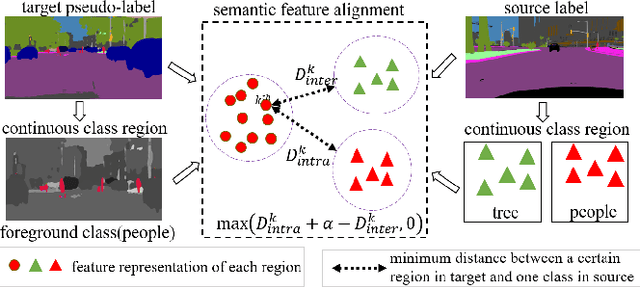
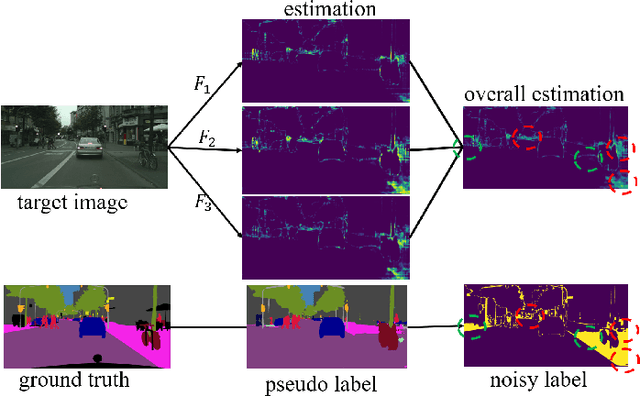
Pseudo-labelling is a popular technique in unsuper-vised domain adaptation for semantic segmentation. However, pseudo labels are noisy and inevitably have confirmation bias due to the discrepancy between source and target domains and training process. In this paper, we train the model by the pseudo labels which are implicitly produced by itself to learn new complementary knowledge about target domain. Specifically, we propose a tri-learning architecture, where every two branches produce the pseudo labels to train the third one. And we align the pseudo labels based on the similarity of the probability distributions for each two branches. To further implicitly utilize the pseudo labels, we maximize the distances of features for different classes and minimize the distances for the same classes by triplet loss. Extensive experiments on GTA5 to Cityscapes and SYNTHIA to Cityscapes tasks show that the proposed method has considerable improvements.