 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer in Transformer
Paper and Code
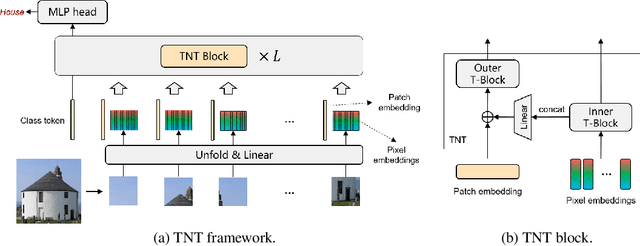

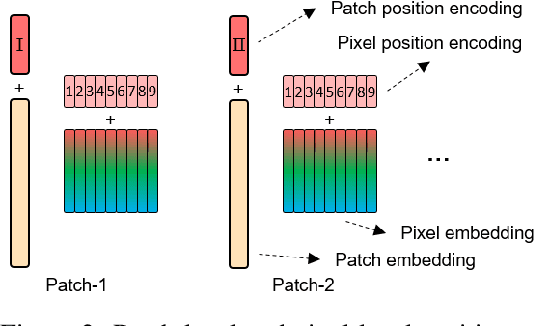
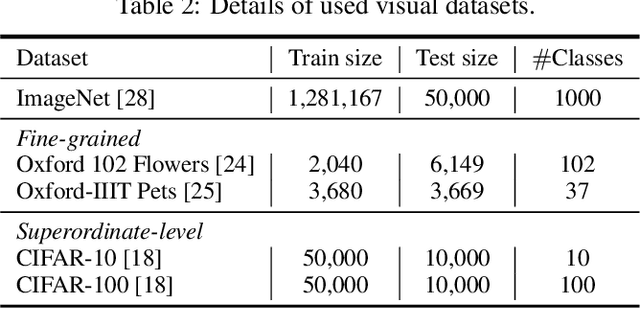
Transformer is a type of self-attention-based neural networks originally applied for NLP tasks. Recently, pure transformer-based models are proposed to solve computer vision problems. These visual transformers usually view an image as a sequence of patches while they ignore the intrinsic structure information inside each patch. In this paper, we propose a novel Transformer-iN-Transformer (TNT) model for modeling both patch-level and pixel-level representation. In each TNT block, an outer transformer block is utilized to process patch embeddings, and an inner transformer block extracts local features from pixel embeddings. The pixel-level feature is projected to the space of patch embedding by a linear transformation layer and then added into the patch. By stacking the TNT blocks, we build the TNT model for image recognition. Experiments on ImageNet benchmark and downstream tasks demonstrate the superiority and efficiency of the proposed TNT architecture. For example, our TNT achieves $81.3\%$ top-1 accuracy on ImageNet which is $1.5\%$ higher than that of DeiT with similar computational cost. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/TNT.