 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLOSE: Curriculum Learning On the Sharing Extent Towards Better One-shot NAS
Paper and Code
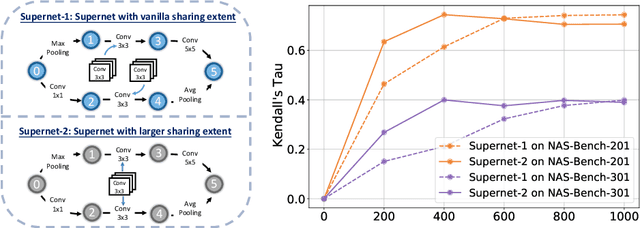
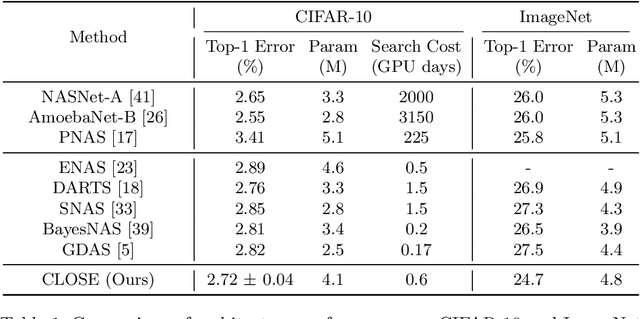
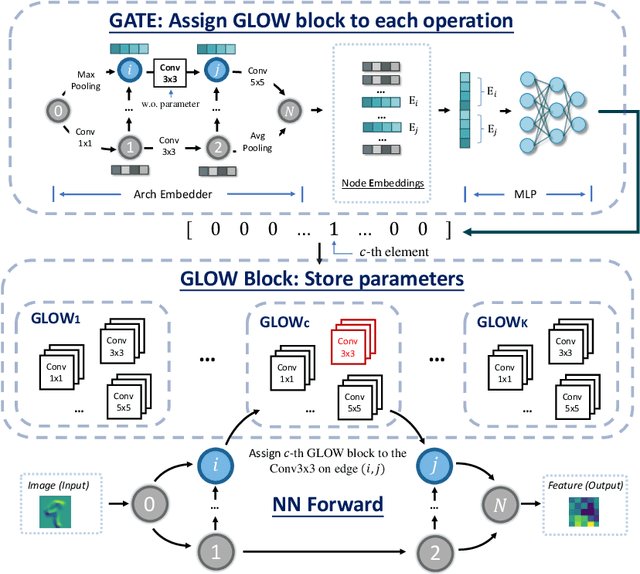

One-shot Neural Architecture Search (NAS) has been widely used to discover architectures due to its efficiency. However, previous studies reveal that one-shot performance estimations of architectures might not be well correlated with their performances in stand-alone training because of the excessive sharing of operation parameters (i.e., large sharing extent) between architectures. Thus, recent methods construct even more over-parameterized supernets to reduce the sharing extent. But these improved methods introduce a large number of extra parameters and thus cause an undesirable trade-off between the training costs and the ranking quality. To alleviate the above issues, we propose to apply Curriculum Learning On Sharing Extent (CLOSE) to train the supernet both efficiently and effectively. Specifically, we train the supernet with a large sharing extent (an easier curriculum) at the beginning and gradually decrease the sharing extent of the supernet (a harder curriculum). To support this training strategy, we design a novel supernet (CLOSENet) that decouples the parameters from operations to realize a flexible sharing scheme and adjustable sharing extent. Extensive experiments demonstrate that CLOSE can obtain a better ranking quality across different computational budget constraints than other one-shot supernets, and is able to discover superior architectures when combined with various search strategies. Code is available at https://github.com/walkerning/aw_nas.