 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrganizing Background to Explore Latent Classes for Incremental Few-shot Semantic Segmentation
May 29, 2024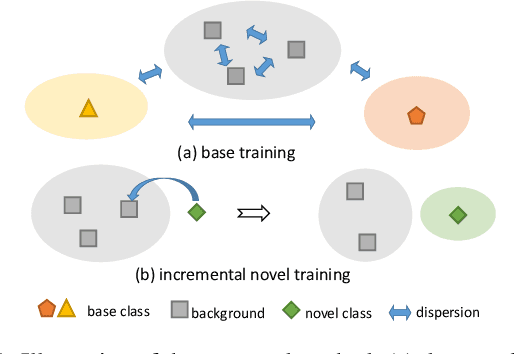
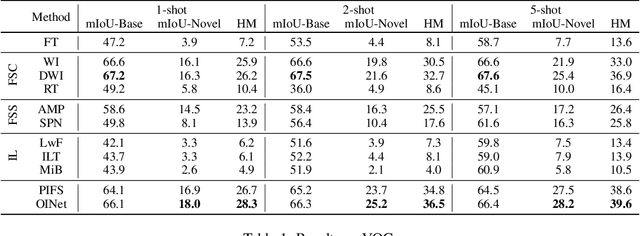
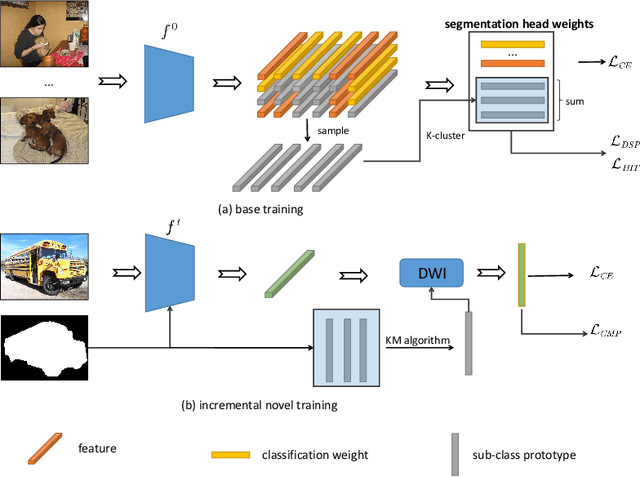
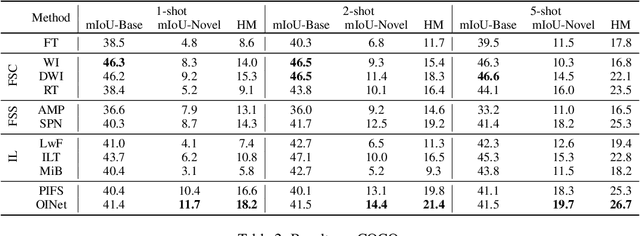
The goal of incremental Few-shot Semantic Segmentation (iFSS) is to extend pre-trained segmentation models to new classes via few annotated images without access to old training data. During incrementally learning novel classes, the data distribution of old classes will be destroyed, leading to catastrophic forgetting. Meanwhile, the novel classes have only few samples, making models impossible to learn the satisfying representations of novel classes. For the iFSS problem, we propose a network called OINet, i.e., the background embedding space \textbf{O}rganization and prototype \textbf{I}nherit Network. Specifically, when training base classes, OINet uses multiple classification heads for the background and sets multiple sub-class prototypes to reserve embedding space for the latent novel classes. During incrementally learning novel classes, we propose a strategy to select the sub-class prototypes that best match the current learning novel classes and make the novel classes inherit the selected prototypes' embedding space. This operation allows the novel classes to be registered in the embedding space using few samples without affecting the distribution of the base classes. Results on Pascal-VOC and COCO show that OINet achieves a new state of the art.
Lifelong Learning and Selective Forgetting via Contrastive Strategy
May 28, 2024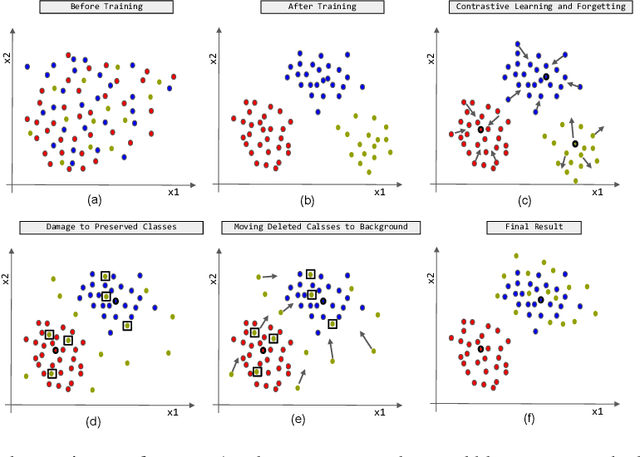
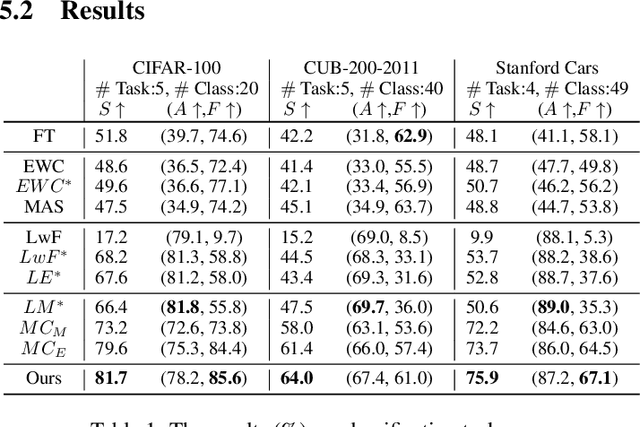
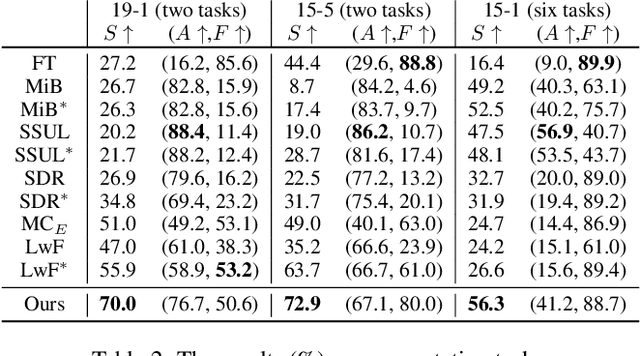
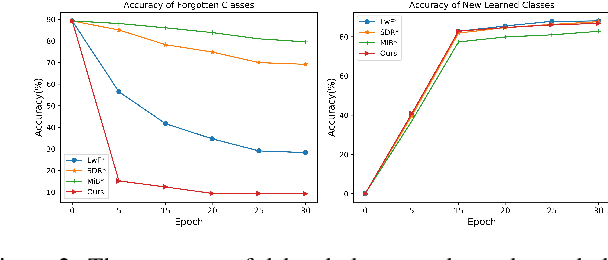
Lifelong learning aims to train a model with good performance for new tasks while retaining the capacity of previous tasks. However, some practical scenarios require the system to forget undesirable knowledge due to privacy issues, which is called selective forgetting. The joint task of the two is dubbed Learning with Selective Forgetting (LSF). In this paper, we propose a new framework based on contrastive strategy for LSF. Specifically, for the preserved classes (tasks), we make features extracted from different samples within a same class compacted. And for the deleted classes, we make the features from different samples of a same class dispersed and irregular, i.e., the network does not have any regular response to samples from a specific deleted class as if the network has no training at all. Through maintaining or disturbing the feature distribution, the forgetting and memory of different classes can be or independent of each other. Experiments are conducted on four benchmark datasets, and our method acieves new state-of-the-art.
The Binary Quantized Neural Network for Dense Prediction via Specially Designed Upsampling and Attention
May 28, 2024Deep learning-based information processing consumes long time and requires huge computing resources, especially for dense prediction tasks which require an output for each pixel, like semantic segmentation and salient object detection. There are mainly two challenges for quantization of dense prediction tasks. Firstly, directly applying the upsampling operation that dense prediction tasks require is extremely crude and causes unacceptable accuracy reduction. Secondly, the complex structure of dense prediction networks means it is difficult to maintain a fast speed as well as a high accuracy when performing quantization. In this paper, we propose an effective upsampling method and an efficient attention computation strategy to transfer the success of the binary neural networks (BNN) from single prediction tasks to dense prediction tasks. Firstly, we design a simple and robust multi-branch parallel upsampling structure to achieve the high accuracy. Then we further optimize the attention method which plays an important role in segmentation but has huge computation complexity. Our attention method can reduce the computational complexity by a factor of one hundred times but retain the original effect. Experiments on Cityscapes, KITTI road, and ECSSD fully show the effectiveness of our work.