 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning from Scene Embeddings for End-to-End Autonomous Driving
Paper and Code
Mar 14, 2025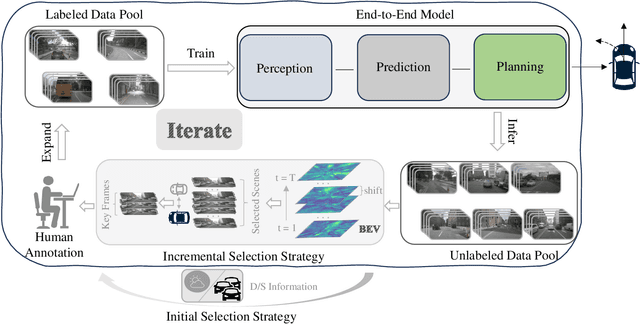
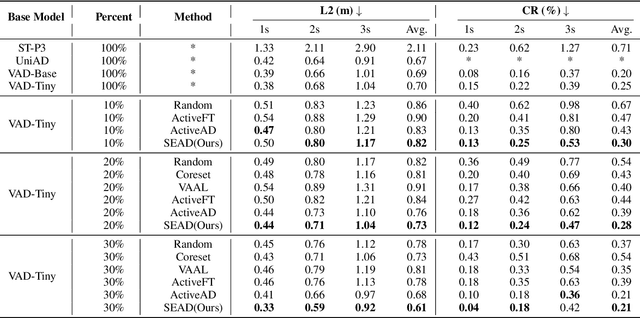
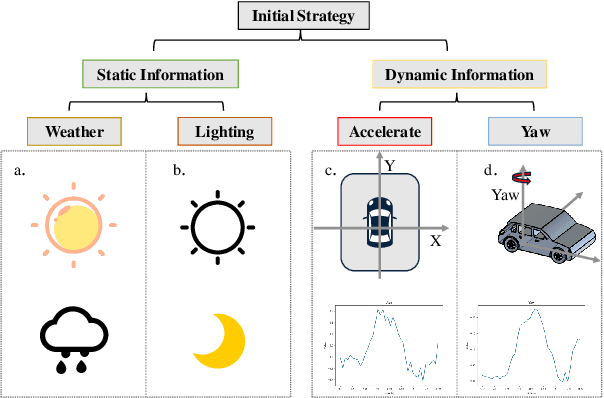
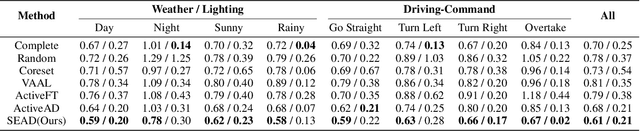
In the field of autonomous driving, end-to-end deep learning models show great potential by learning driving decisions directly from sensor data. However, training these models requires large amounts of labeled data, which is time-consuming and expensive. Considering that the real-world driving data exhibits a long-tailed distribution where simple scenarios constitute a majority part of the data, we are thus inspired to identify the most challenging scenarios within it. Subsequently, we can efficiently improve the performance of the model by training with the selected data of the highest value. Prior research has focused on the selection of valuable data by empirically designed strategies. However, manually designed methods suffer from being less generalizable to new data distributions. Observing that the BEV (Bird's Eye View) features in end-to-end models contain all the information required to represent the scenario, we propose an active learning framework that relies on these vectorized scene-level features, called SEAD. The framework selects initial data based on driving-environmental information and incremental data based on BEV features. Experiments show that we only need 30\% of the nuScenes training data to achieve performance close to what can be achieved with the full dataset. The source code will be released.