 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Quantization-Aware Training on Segment Anything Model in Medical Images and Its Deployment
Dec 15, 2024Medical image segmentation is a critical component of clinical practice, and the state-of-the-art MedSAM model has significantly advanced this field. Nevertheless, critiques highlight that MedSAM demands substantial computational resources during inference. To address this issue, the CVPR 2024 MedSAM on Laptop Challenge was established to find an optimal balance between accuracy and processing speed. In this paper, we introduce a quantization-aware training pipeline designed to efficiently quantize the Segment Anything Model for medical images and deploy it using the OpenVINO inference engine. This pipeline optimizes both training time and disk storage. Our experimental results confirm that this approach considerably enhances processing speed over the baseline, while still achieving an acceptable accuracy level. The training script, inference script, and quantized model are publicly accessible at https://github.com/AVC2-UESTC/QMedSAM.
NPR: Nocturnal Place Recognition in Streets
Apr 17, 2023



Visual Place Recognition (VPR) is the task of retrieving database images similar to a query photo by comparing it to a large database of known images. In real-world applications, extreme illumination changes caused by query images taken at night pose a significant obstacle that VPR needs to overcome. However, a training set with day-night correspondence for city-scale, street-level VPR does not exist. To address this challenge, we propose a novel pipeline that divides VPR and conquers Nocturnal Place Recognition (NPR). Specifically, we first established a street-level day-night dataset, NightStreet, and used it to train an unpaired image-to-image translation model. Then we used this model to process existing large-scale VPR datasets to generate the VPR-Night datasets and demonstrated how to combine them with two popular VPR pipelines. Finally, we proposed a divide-and-conquer VPR framework and provided explanations at the theoretical, experimental, and application levels. Under our framework, previous methods can significantly improve performance on two public datasets, including the top-ranked method.
Scale-Net: Learning to Reduce Scale Differences for Large-Scale Invariant Image Matching
Dec 20, 2021
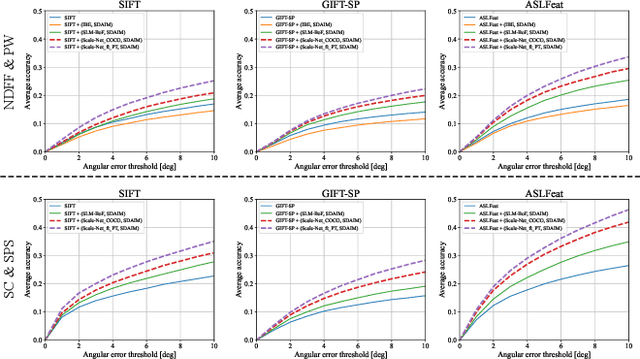
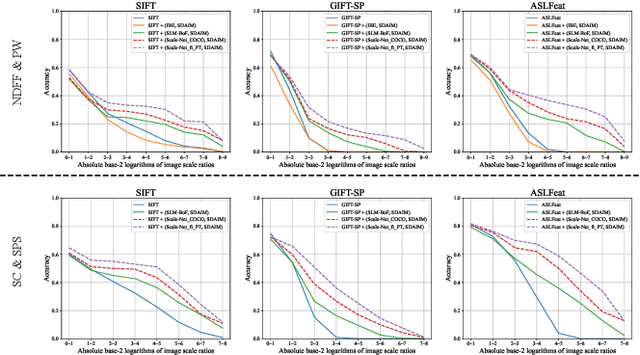

Most image matching methods perform poorly when encountering large scale changes in images. To solve this problem, firstly, we propose a scale-difference-aware image matching method (SDAIM) that reduces image scale differences before local feature extraction, via resizing both images of an image pair according to an estimated scale ratio. Secondly, in order to accurately estimate the scale ratio, we propose a covisibility-attention-reinforced matching module (CVARM) and then design a novel neural network, termed as Scale-Net, based on CVARM. The proposed CVARM can lay more stress on covisible areas within the image pair and suppress the distraction from those areas visible in only one image. Quantitative and qualitative experiments confirm that the proposed Scale-Net has higher scale ratio estimation accuracy and much better generalization ability compared with all the existing scale ratio estimation methods. Further experiments on image matching and relative pose estimation tasks demonstrate that our SDAIM and Scale-Net are able to greatly boost the performance of representative local features and state-of-the-art local feature matching methods.