 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaRK-Detect: Towards Efficient Multi-Task Satellite Imagery Road Extraction via Patch-Wise Keypoints Detection
Feb 26, 2023

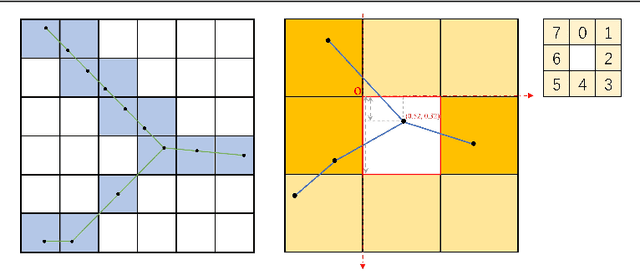
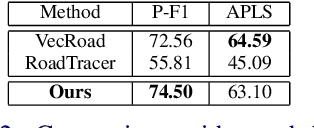
Automatically extracting roads from satellite imagery is a fundamental yet challenging computer vision task in the field of remote sensing. Pixel-wise semantic segmentation-based approaches and graph-based approaches are two prevailing schemes. However, prior works show the imperfections that semantic segmentation-based approaches yield road graphs with low connectivity, while graph-based methods with iterative exploring paradigms and smaller receptive fields focus more on local information and are also time-consuming. In this paper, we propose a new scheme for multi-task satellite imagery road extraction, Patch-wise Road Keypoints Detection (PaRK-Detect). Building on top of D-LinkNet architecture and adopting the structure of keypoint detection, our framework predicts the position of patch-wise road keypoints and the adjacent relationships between them to construct road graphs in a single pass. Meanwhile, the multi-task framework also performs pixel-wise semantic segmentation and generates road segmentation masks. We evaluate our approach against the existing state-of-the-art methods on DeepGlobe, Massachusetts Roads, and RoadTracer datasets and achieve competitive or better results. We also demonstrate a considerable outperformance in terms of inference speed.
* Accepted at BMVC 2022 (Oral). 13 pages, 5 figures. https://bmvc2022.mpi-inf.mpg.de/381/
Bridging CLIP and StyleGAN through Latent Alignment for Image Editing
Oct 10, 2022

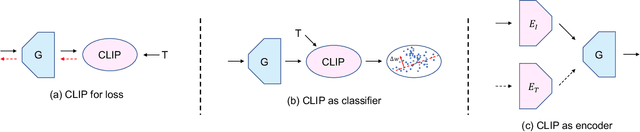
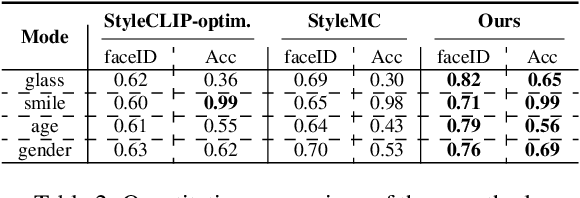
Text-driven image manipulation is developed since the vision-language model (CLIP) has been proposed. Previous work has adopted CLIP to design a text-image consistency-based objective to address this issue. However, these methods require either test-time optimization or image feature cluster analysis for single-mode manipulation direction. In this paper, we manage to achieve inference-time optimization-free diverse manipulation direction mining by bridging CLIP and StyleGAN through Latent Alignment (CSLA). More specifically, our efforts consist of three parts: 1) a data-free training strategy to train latent mappers to bridge the latent space of CLIP and StyleGAN; 2) for more precise mapping, temporal relative consistency is proposed to address the knowledge distribution bias problem among different latent spaces; 3) to refine the mapped latent in s space, adaptive style mixing is also proposed. With this mapping scheme, we can achieve GAN inversion, text-to-image generation and text-driven image manipulation. Qualitative and quantitative comparisons are made to demonstrate the effectiveness of our method.
ITTR: Unpaired Image-to-Image Translation with Transformers
Mar 30, 2022
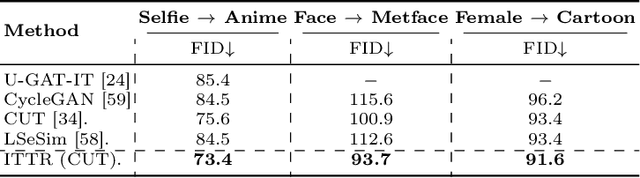

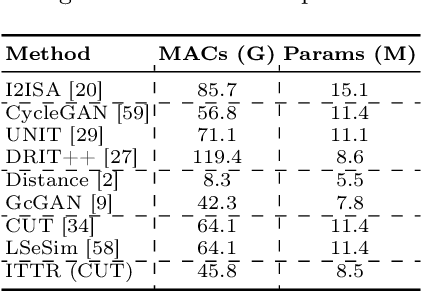
Unpaired image-to-image translation is to translate an image from a source domain to a target domain without paired training data. By utilizing CNN in extracting local semantics, various techniques have been developed to improve the translation performance. However, CNN-based generators lack the ability to capture long-range dependency to well exploit global semantics. Recently, Vision Transformers have been widely investigated for recognition tasks. Though appealing, it is inappropriate to simply transfer a recognition-based vision transformer to image-to-image translation due to the generation difficulty and the computation limitation. In this paper, we propose an effective and efficient architecture for unpaired Image-to-Image Translation with Transformers (ITTR). It has two main designs: 1) hybrid perception block (HPB) for token mixing from different receptive fields to utilize global semantics; 2) dual pruned self-attention (DPSA) to sharply reduce the computational complexity. Our ITTR outperforms the state-of-the-arts for unpaired image-to-image translation on six benchmark datasets.