 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcological Reinforcement Learning
Paper and Code


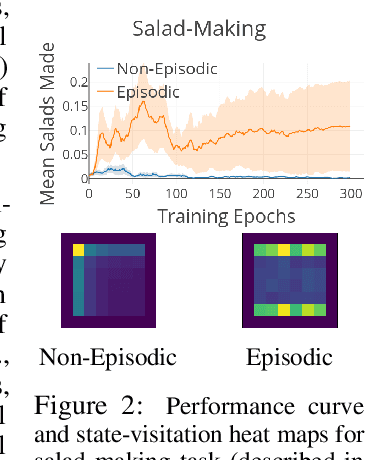

Much of the current work on reinforcement learning studies episodic settings, where the agent is reset between trials to an initial state distribution, often with well-shaped reward functions. Non-episodic settings, where the agent must learn through continuous interaction with the world without resets, and where the agent receives only delayed and sparse reward signals, is substantially more difficult, but arguably more realistic considering real-world environments do not present the learner with a convenient "reset mechanism" and easy reward shaping. In this paper, instead of studying algorithmic improvements that can address such non-episodic and sparse reward settings, we instead study the kinds of environment properties that can make learning under such conditions easier. Understanding how properties of the environment impact the performance of reinforcement learning agents can help us to structure our tasks in ways that make learning tractable. We first discuss what we term "environment shaping" -- modifications to the environment that provide an alternative to reward shaping, and may be easier to implement. We then discuss an even simpler property that we refer to as "dynamism," which describes the degree to which the environment changes independent of the agent's actions and can be measured by environment transition entropy. Surprisingly, we find that even this property can substantially alleviate the challenges associated with non-episodic RL in sparse reward settings. We provide an empirical evaluation on a set of new tasks focused on non-episodic learning with sparse rewards. Through this study, we hope to shift the focus of the community towards analyzing how properties of the environment can affect learning and the ultimate type of behavior that is learned via RL.