Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Grammatical Error Correction using Iterative Decoding
Paper and Code

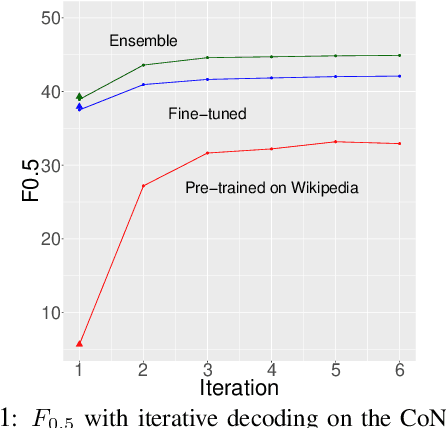
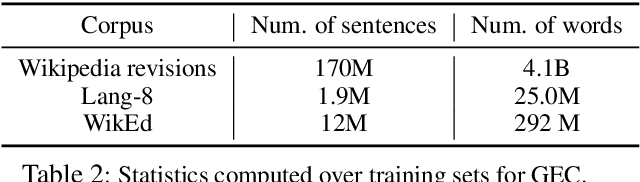

We describe an approach to Grammatical Error Correction (GEC) that is effective at making use of models trained on large amounts of weakly supervised bitext. We train the Transformer sequence-to-sequence model on 4B tokens of Wikipedia revisions and employ an iterative decoding strategy that is tailored to the loosely-supervised nature of the Wikipedia training corpus. Finetuning on the Lang-8 corpus and ensembling yields an F0.5 of 58.3 on the CoNLL'14 benchmark and a GLEU of 62.4 on JFLEG. The combination of weakly supervised training and iterative decoding obtains an F0.5 of 48.2 on CoNLL'14 even without using any labeled GEC data.
View paper on