 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoder Denoising Pretraining for Semantic Segmentation
May 23, 2022
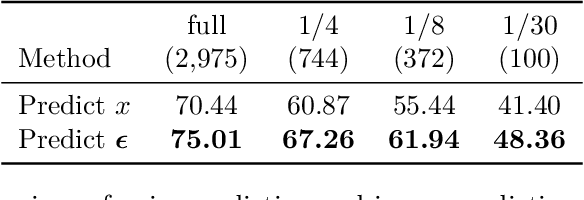
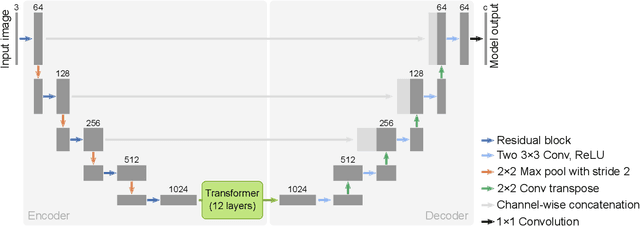
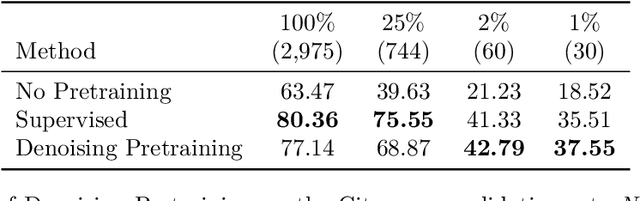
Semantic segmentation labels are expensive and time consuming to acquire. Hence, pretraining is commonly used to improve the label-efficiency of segmentation models. Typically, the encoder of a segmentation model is pretrained as a classifier and the decoder is randomly initialized. Here, we argue that random initialization of the decoder can be suboptimal, especially when few labeled examples are available. We propose a decoder pretraining approach based on denoising, which can be combined with supervised pretraining of the encoder. We find that decoder denoising pretraining on the ImageNet dataset strongly outperforms encoder-only supervised pretraining. Despite its simplicity, decoder denoising pretraining achieves state-of-the-art results on label-efficient semantic segmentation and offers considerable gains on the Cityscapes, Pascal Context, and ADE20K datasets.