 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiRA: Sparse Mixture of Low Rank Adaptation
Nov 15, 2023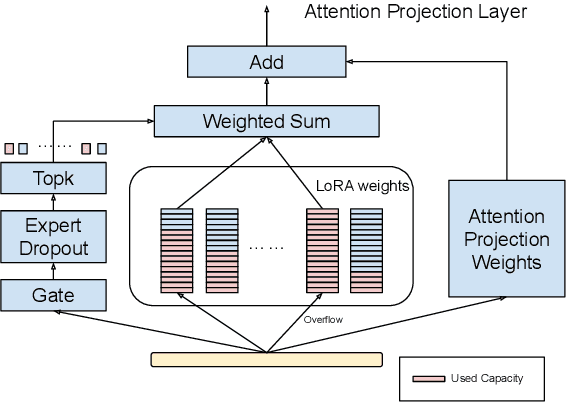



Parameter Efficient Tuning has been an prominent approach to adapt the Large Language Model to downstream tasks. Most previous works considers adding the dense trainable parameters, where all parameters are used to adapt certain task. We found this less effective empirically using the example of LoRA that introducing more trainable parameters does not help. Motivated by this we investigate the importance of leveraging "sparse" computation and propose SiRA: sparse mixture of low rank adaption. SiRA leverages the Sparse Mixture of Expert(SMoE) to boost the performance of LoRA. Specifically it enforces the top $k$ experts routing with a capacity limit restricting the maximum number of tokens each expert can process. We propose a novel and simple expert dropout on top of gating network to reduce the over-fitting issue. Through extensive experiments, we verify SiRA performs better than LoRA and other mixture of expert approaches across different single tasks and multitask settings.
RewriteLM: An Instruction-Tuned Large Language Model for Text Rewriting
May 25, 2023



Large Language Models (LLMs) have demonstrated impressive zero-shot capabilities in long-form text generation tasks expressed through natural language instructions. However, user expectations for long-form text rewriting is high, and unintended rewrites (''hallucinations'') produced by the model can negatively impact its overall performance. Existing evaluation benchmarks primarily focus on limited rewriting styles and sentence-level rewriting rather than long-form open-ended rewriting.We introduce OpenRewriteEval, a novel benchmark that covers a wide variety of rewriting types expressed through natural language instructions. It is specifically designed to facilitate the evaluation of open-ended rewriting of long-form texts. In addition, we propose a strong baseline model, RewriteLM, an instruction-tuned large language model for long-form text rewriting. We develop new strategies that facilitate the generation of diverse instructions and preference data with minimal human intervention. We conduct empirical experiments and demonstrate that our model outperforms the current state-of-the-art LLMs in text rewriting. Specifically, it excels in preserving the essential content and meaning of the source text, minimizing the generation of ''hallucinated'' content, while showcasing the ability to generate rewrites with diverse wording and structures.