 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Fleet Efficiency: Analyzing and Optimizing Large-Scale Google TPU Systems with ML Productivity Goodput
Feb 10, 2025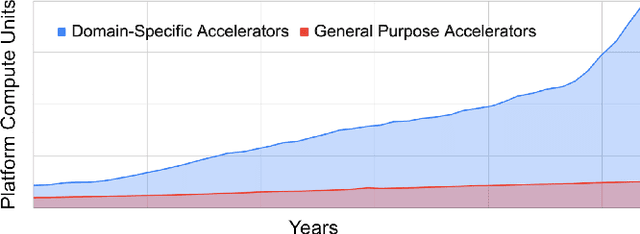

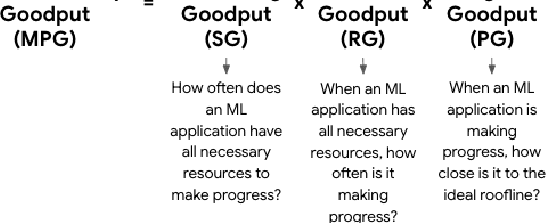

Recent years have seen the emergence of machine learning (ML) workloads deployed in warehouse-scale computing (WSC) settings, also known as ML fleets. As the computational demands placed on ML fleets have increased due to the rise of large models and growing demand for ML applications, it has become increasingly critical to measure and improve the efficiency of such systems. However, there is not yet an established methodology to characterize ML fleet performance and identify potential performance optimizations accordingly. This paper presents a large-scale analysis of an ML fleet based on Google's TPUs, introducing a framework to capture fleet-wide efficiency, systematically evaluate performance characteristics, and identify optimization strategies for the fleet. We begin by defining an ML fleet, outlining its components, and analyzing an example Google ML fleet in production comprising thousands of accelerators running diverse workloads. Our study reveals several critical insights: first, ML fleets extend beyond the hardware layer, with model, data, framework, compiler, and scheduling layers significantly impacting performance; second, the heterogeneous nature of ML fleets poses challenges in characterizing individual workload performance; and third, traditional utilization-based metrics prove insufficient for ML fleet characterization. To address these challenges, we present the "ML Productivity Goodput" (MPG) metric to measure ML fleet efficiency. We show how to leverage this metric to characterize the fleet across the ML system stack. We also present methods to identify and optimize performance bottlenecks using MPG, providing strategies for managing warehouse-scale ML systems in general. Lastly, we demonstrate quantitative evaluations from applying these methods to a real ML fleet for internal-facing Google TPU workloads, where we observed tangible improvements.