 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Linguistically Enhanced Embeddings for Open Information Extraction
Mar 20, 2024Open Information Extraction (OIE) is a structured prediction (SP) task in Natural Language Processing (NLP) that aims to extract structured $n$-ary tuples - usually subject-relation-object triples - from free text. The word embeddings in the input text can be enhanced with linguistic features, usually Part-of-Speech (PoS) and Syntactic Dependency Parse (SynDP) labels. However, past enhancement techniques cannot leverage the power of pretrained language models (PLMs), which themselves have been hardly used for OIE. To bridge this gap, we are the first to leverage linguistic features with a Seq2Seq PLM for OIE. We do so by introducing two methods - Weighted Addition and Linearized Concatenation. Our work can give any neural OIE architecture the key performance boost from both PLMs and linguistic features in one go. In our settings, this shows wide improvements of up to 24.9%, 27.3% and 14.9% on Precision, Recall and F1 scores respectively over the baseline. Beyond this, we address other important challenges in the field: to reduce compute overheads with the features, we are the first ones to exploit Semantic Dependency Parse (SemDP) tags; to address flaws in current datasets, we create a clean synthetic dataset; finally, we contribute the first known study of OIE behaviour in SP models.
Dyna-AIL : Adversarial Imitation Learning by Planning
Mar 08, 2019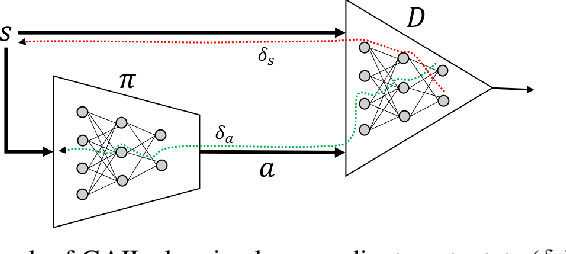
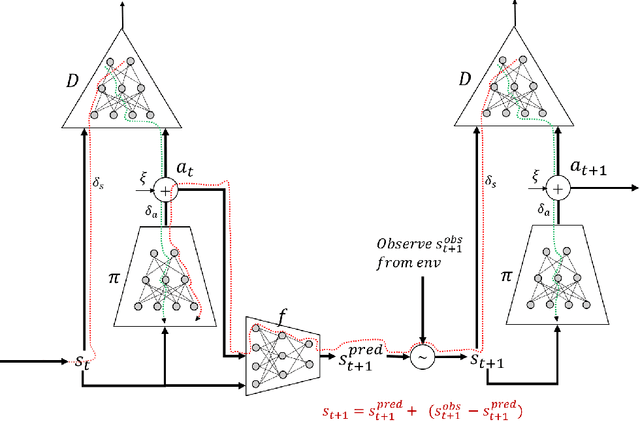
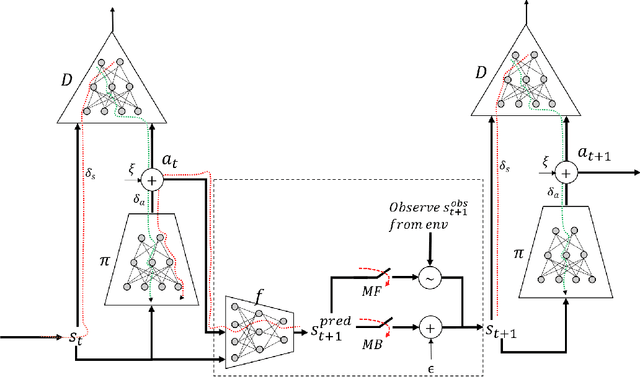
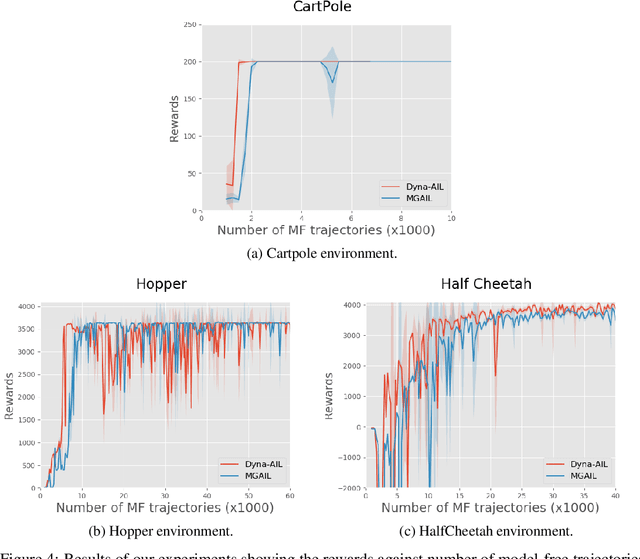
Adversarial methods for imitation learning have been shown to perform well on various control tasks. However, they require a large number of environment interactions for convergence. In this paper, we propose an end-to-end differentiable adversarial imitation learning algorithm in a Dyna-like framework for switching between model-based planning and model-free learning from expert data. Our results on both discrete and continuous environments show that our approach of using model-based planning along with model-free learning converges to an optimal policy with fewer number of environment interactions in comparison to the state-of-the-art learning methods.